软件架构
什么是Web架构
Web架构包括数据库、消息队列、缓存、用户界面等多个组件,它们相互结合,形成在线服务
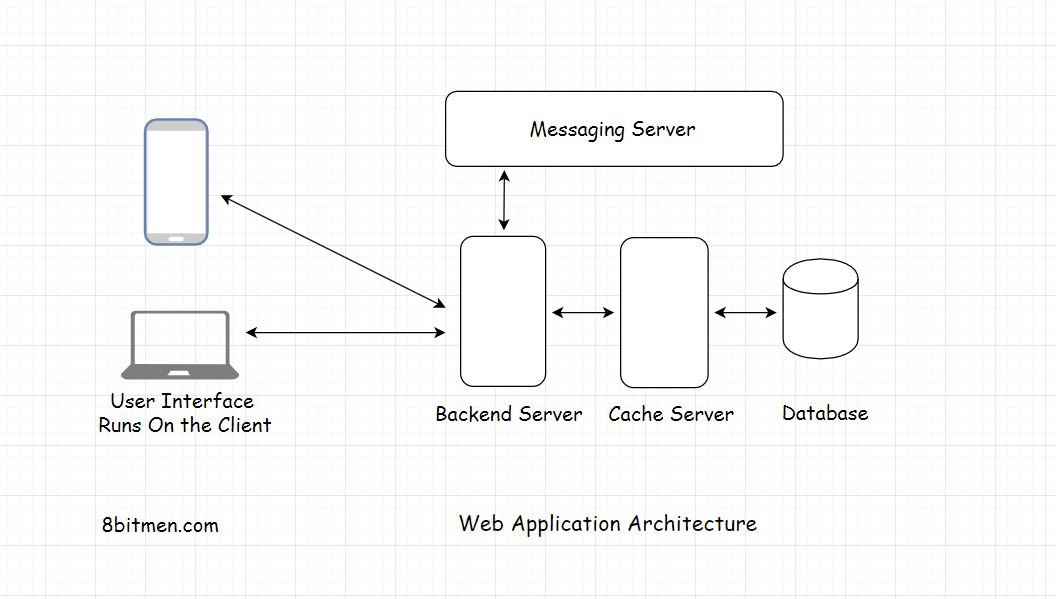
这是web应用程序的典型架构,在大多数在线运行的应用程序中使用。
如果我们对图中所涉及的组件有一个了解,那么我们总是可以在这个体系结构的基础上构建更复杂的需求。
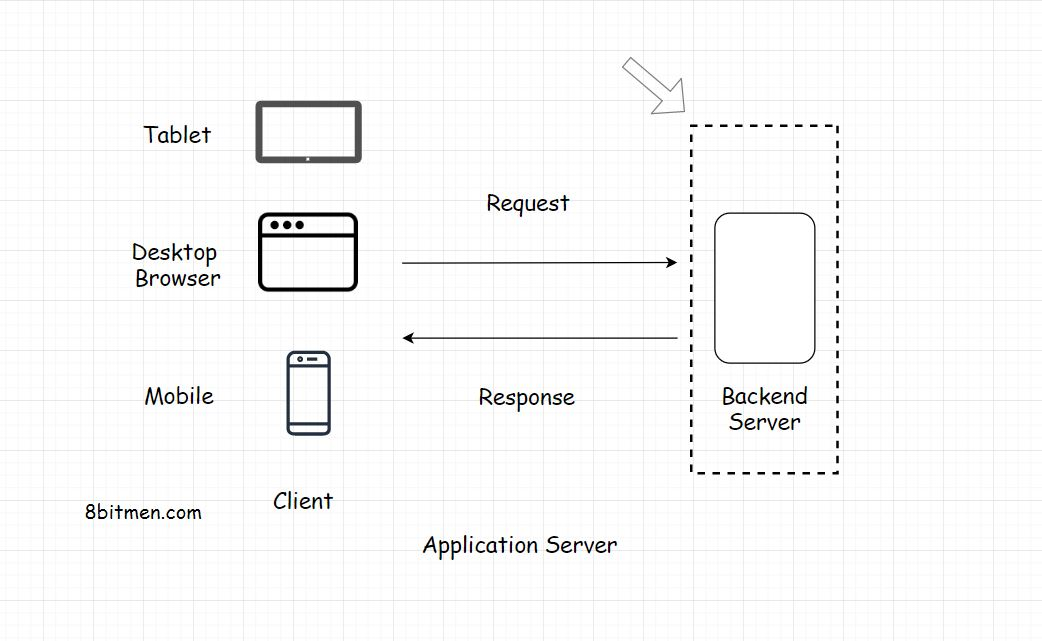
Client Server Architecture客户服务器结构
在讨论两层、三层和n层架构时,我们已经对客户端-服务器架构有了一些了解。现在我们来详细看看。
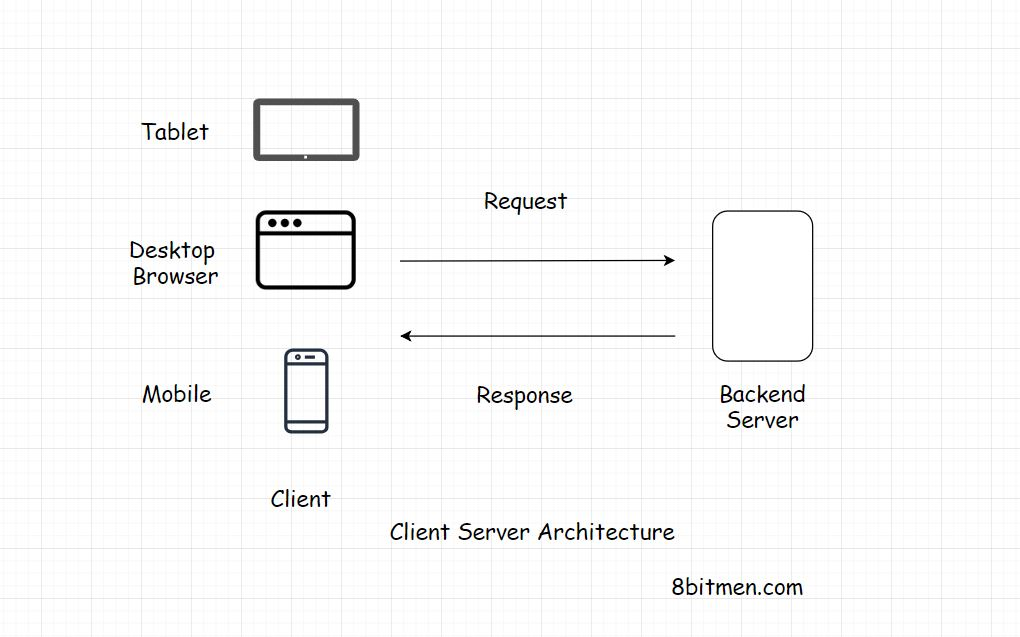
客户端-服务器架构是web的基本构件。
该体系结构在请求-响应模型上工作。客户端向服务器发送请求以获取信息&服务器响应它。
你浏览的每个网站,无论是Wordpress博客还是Facebook、Twitter或银行应用程序,都是建立在客户-服务器架构上的。
只有非常小的比例的业务网站和应用程序使用peer to peer体系结构,这与客户机-服务器不同。
client
客户端保存我们的用户界面。用户界面是应用程序的表示部分。它是用Html, JavaScript, CSS编写的,并负责应用程序的外观和感觉。
用户界面在客户机上运行。客户端可以是移动应用程序、台式机或像iPad这样的平板电脑。它也可以是基于web的控制台,运行命令与后端服务器交互。
简单地说,客户端就是我们应用程序的窗口。在业界,编写基于web的用户界面的开源技术有ReactJS、AngularJS、VueJS、Jquery等。所有这些库都使用JavaScript。
编写前端也有很多其他的技术,我只是列出了目前最流行的几种。
不同的平台需要不同的框架和库来编写前端。例如,运行Android的手机将需要一套不同的工具,运行苹果或Windows操作系统的手机将需要一套不同的工具
Types of Client
Thin Client
瘦客户机是仅持有应用程序用户界面的客户机。它没有任何形式的商业逻辑。对于每个操作,客户端都向后端服务器发送一个请求。就像在三层应用程序中一样。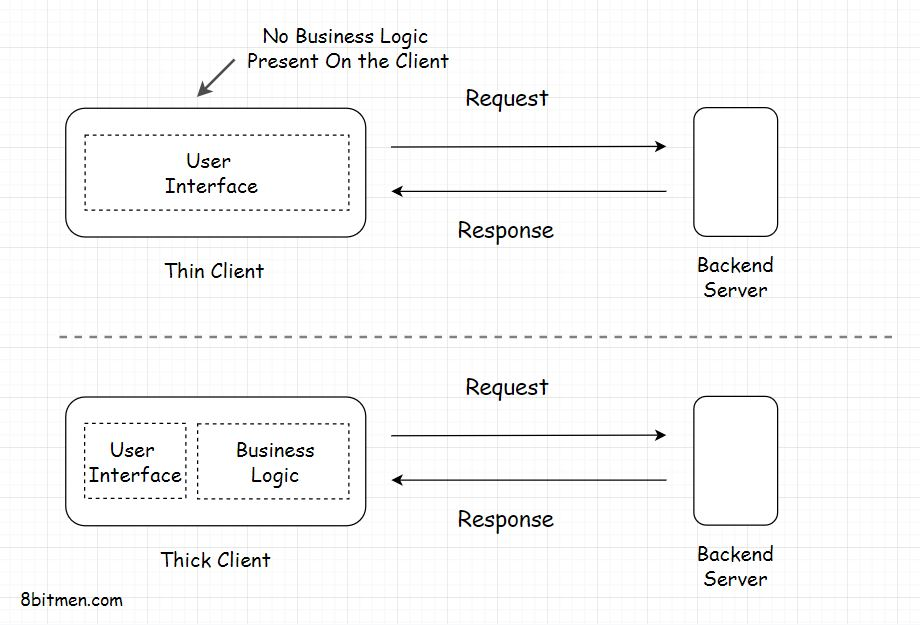
Thick Client( Fat client)
胖客户机持有全部或部分业务逻辑。这些是两层应用程序。我们已经讲过了,如果你还记得的话。胖客户端的典型例子是实用程序、在线游戏等
Server
web服务器的主要任务是接收来自客户端的请求,并根据从客户端收到的请求参数执行业务逻辑后提供响应。
每一个在线运行的服务都需要一个服务器来运行。运行web应用程序的服务器通常被称为应用服务器。
除了应用程序服务器之外,还有其他类型的服务器,它们被分配特定的任务,例如
代理服务器
邮件服务器
文件服务器
虚拟服务器
服务器配置和类型可以根据用例的不同而不同。
例如,如果我们运行用Java编写的后端应用程序代码,我们会选择Apache Tomcat或Jetty
对于简单的用例,比如托管网站,我们会选择Apache HTTP服务器。
一个web应用程序的所有组件都需要一个服务器来运行。可以是数据库、消息队列、缓存或任何其他组件。在现代应用程序开发中,甚至用户界面也单独驻留在专用服务器上
Server-Side Rendering
SSR 后端渲染技术,开发人员使用服务器在后台呈现用户界面,然后将呈现的数据发送给客户端。这种技术被称为服务器端渲染。我将在后面的课程中讨论客户端和服务器端渲染的优缺点。
客户端渲染Vs服务器端渲染(Client-Side Vs Server-Side Rendering)
当用户从服务器请求一个网页&浏览器收到响应。它必须以HTML页面的形式在窗口上呈现响应
为此,浏览器有几个组件,例如:
- 浏览器引擎
- 渲染引擎
- JavaScript解释器
- 网络和UI后端
- 数据存储等
渲染引擎构建DOM树,渲染并绘制结构。
Server-Side Rendering
为了避免客户端的渲染时间,开发人员经常在服务器端渲染UI,在那里生成HTML,然后直接将HTML页面发送给UI。这种技术称为服务器端呈现。它确保更快的UI渲染,避免UI加载时间在浏览器窗口,因为页面已经创建&浏览器不需要做很多组装和渲染工作。
服务器端呈现方法非常适合交付静态内容,比如WordPress博客。这也有利于搜索引擎优化,因为爬虫可以很容易地阅读生成的内容。
然而,现代网站高度依赖于Ajax。在这样的网站中,特定模块或页面部分的内容必须在运行中获取和呈现
因此,服务器端呈现并没有多大帮助。对于每一个ajax请求,该方法不只是向客户机发送所需的内容,而是在服务器上生成整个页面。这个过程会消耗不必要的带宽,也不能提供流畅的用户体验
这样做的一大缺点是,一旦网站上并发用户的数量增加,就会给服务器带来不必要的负载
Client-side rendering
客户端渲染对于现代的基于ajax的动态网站来说是最好的
尽管我们可以利用一种混合的方法,以最大限度地利用这两种技术。我们可以使用服务器端渲染首页&我们网站上的其他静态内容&使用客户端渲染动态页面
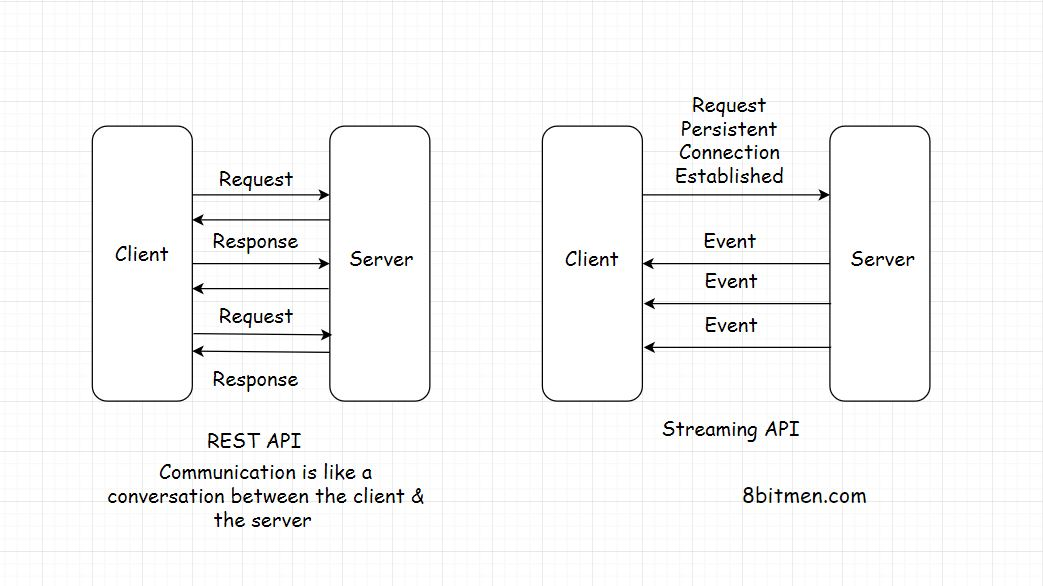
Communication Between the Client & the Server 客户端和服务器之间的通信模型
请求 - 响应模型
HTTP协议
REST API和API端点
使用REST API的真实世界示例
Request-Response Model 请求-响应模型
客户端和服务器有一个请求-响应模型。客户端发送请求,服务器用数据响应。如果没有请求,就没有响应。
HTTP Protocol HTTP协议
整个通信都是通过HTTP协议进行的。它是在万维网上交换数据的协议。HTTP协议是一个请求-响应协议,定义了信息如何在web上传输
它是一个无状态协议,HTTP上的每个进程都是独立执行的,并且不知道以前的进程。
REST API & API Endpoints REST API和API端点
从现代n层web应用程序的上下文来看,每个客户端都必须到达一个REST端点才能从后端获取数据。
后端应用程序代码实现了一个REST-API,作为与外部世界请求的接口。每一个来自客户端的请求,无论是由企业写的请求,还是使用我们数据的第三方开发人员的请求,都必须到达rest端点来获取数据。
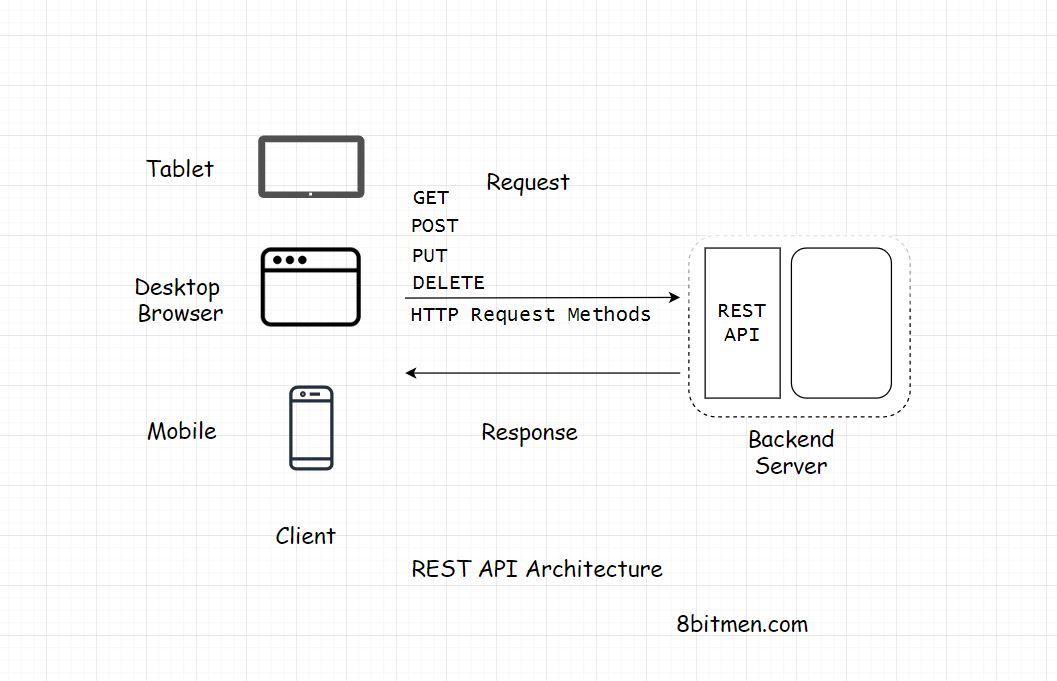
Real World Example Of Using A REST API 使用REST API的真实例子
例如,假设我们想要编写一个应用程序来跟踪我们所有Facebook朋友的生日,并在活动日期前几天给我们发送提醒。
要实现这一点,第一步将是获取我们所有Facebook好友的生日数据。
我们将编写一个客户端,它将访问Facebook社交图API,这是一个REST-API来获取数据&然后在数据上运行我们的业务逻辑。
实现基于rest的API有几个优点。为了更深入地了解它,让我们深入研究它。
REST API
REST API作为客户端和服务器之间通过HTTP进行通信的接口
WHAT IS REST? 什么是REST API
REST代表具象状态转移。它是一种用于实现web服务的软件架构风格。使用REST体系结构风格实现的Web服务称为RESTful Web服务
REST API
REST API是遵循REST体系结构约束的API实现。它充当一个接口。客户端和服务器之间的通信是通过HTTP进行的。REST API利用HTTP方法来建立客户机和服务器之间的通信。REST还允许服务器缓存响应,从而提高应用程序的性能。
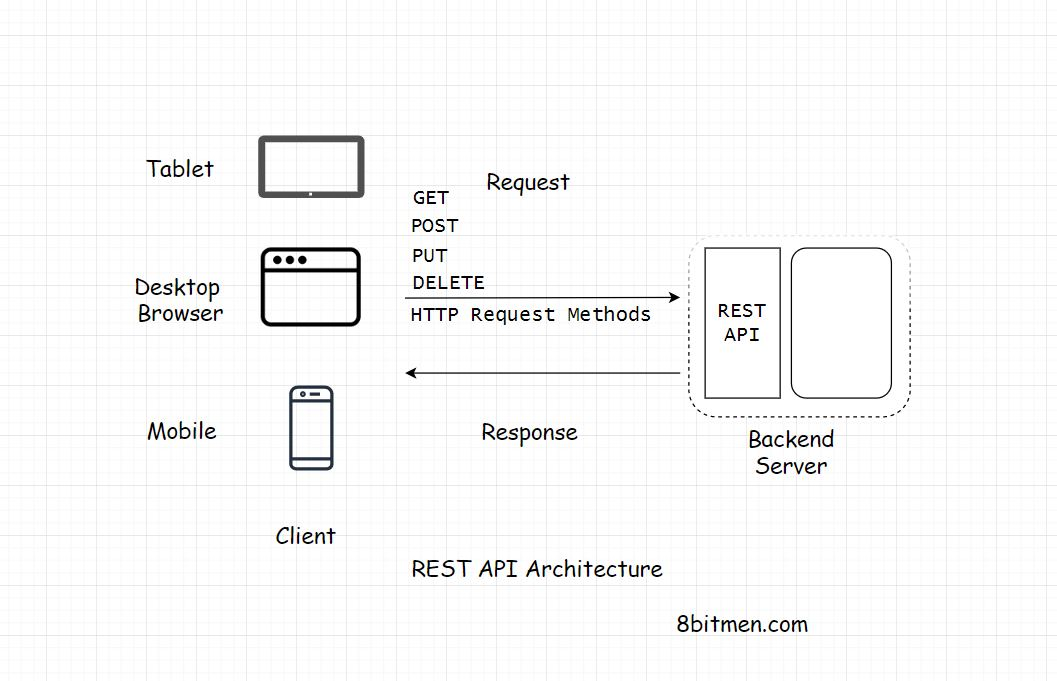
客户端和服务器之间的通信是一个无状态的过程。我的意思是,客户端和服务器之间的每一次通信都像是一次新的通信
从先前的通讯中没有留下任何信息或记忆。因此,每次客户机与后端交互时,它也必须将身份验证信息发送给它。这使后端能够确定客户端是否被授权访问数据。
通过实现REST API,客户端可以获得与之通信的后端端点。这完全解耦了后端和客户端代码
REST Endpoint
REST Endpoint表示服务的URL。例如,https://myservice.com/getuserdetails/ {username}是一个后端端点从服务中获取特定用户的用户详细信息。
基于rest的服务将把这个url公开给它的所有客户端,以使用上述url获取用户详细信息
Decoupling Clients & the Backend Service 解耦客户端和后端服务
随着端点的可用性,后端服务不必担心客户的实施。它只是呼唤其多个客户&“嘿大家,这是资源/信息的URL地址需要。当你需要它时击中它。任何客户所需授权的客户访问资源可以访问它“
开发人员可以针对不同的客户端(手机浏览器、桌面浏览器、平板电脑或API测试工具)使用不同的代码库进行不同的实现。引入新的客户端类型或修改客户端代码对后端服务的功能没有影响,这意味着客户端和后端服务是解耦的
Application Development Before the REST API在REST API之前的应用程序开发
在基于rest的API接口成为行业主流之前。我们经常将后端代码与客户端紧密耦合。JSP (Java服务器页面)就是其中的一个例子。
我们总是将业务逻辑放在JSP标记中。当逻辑扩展到不同的层时,是什么让代码重构和添加新功能变得非常困难
此外,在相同的代码库中,我们必须编写单独的代码/类进行处理来自不同类型客户端的请求。移动客户端的不同servlet以及用于基于Web的客户端的不同之一。
在REST api被广泛使用之后,就不需要担心客户机的类型了。只需提供端点&响应通常包含JSON或任何其他标准数据传输格式的数据。客户将以任何他们想要的方式处理数据。
这为我们减少了许多不必要的工作。此外,添加新客户也变得容易得多。我们可以引入多种类型的新客户端,而不考虑后端实现
在当今的行业格局中,几乎没有没有REST API的在线服务。想要访问任何社交网络的公共数据?使用他们的 REST API
API Gateway
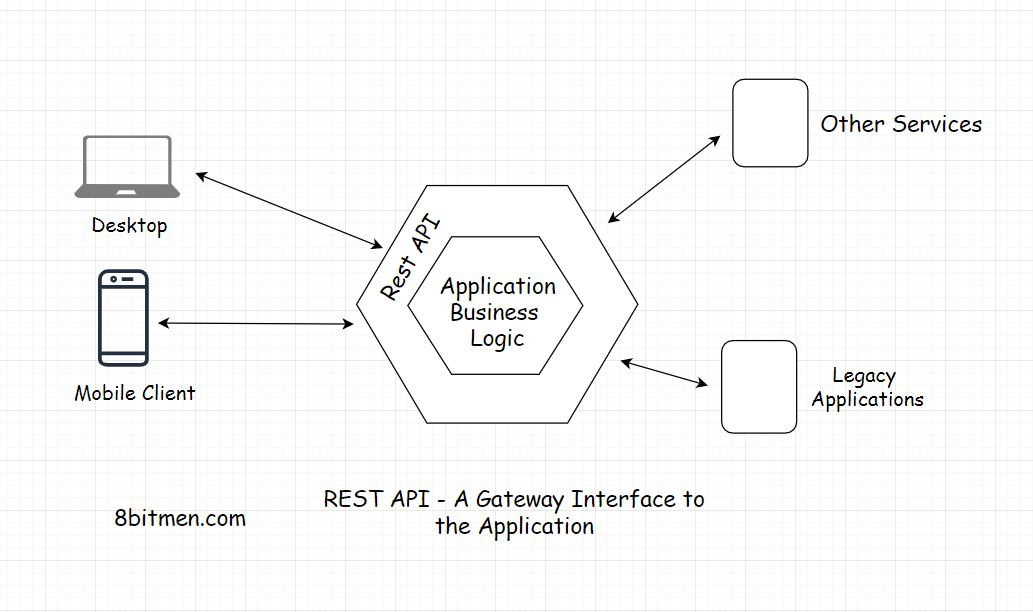
REST-API充当网关,作为进入系统的单一入口点。它封装了业务逻辑。处理所有客户端请求,在提供对应用程序资源的访问之前,负责授权、身份验证、清除输入数据和其他必要的任务
HTTP Push & Pull -介绍
深入了解HTTP Push & Pull机制。我们知道,web上的大多数通信都是通过HTTP进行的,特别是涉及到客户端-服务器架构的时候。
在客户机和服务器之间有两种数据传输模式。HTTP推送和HTTP拉取。让我们看看他们是什么和他们做什么。
HTTP PULL
如前所述,对于每个响应,首先必须有一个请求。客户端发送请求,服务器用数据响应。这是HTTP通信的默认模式,称为HTTP PULL机制。
客户端在需要时从服务器提取数据。它会一直这样做来获取更新的数据。
这里需要注意的重要一点是,对服务器的每个请求和对它的响应都会消耗带宽。服务器上的每一次攻击都会损失业务资金,并增加服务器上的负载。
如果每次客户机发送请求时,服务器上没有可用的更新数据怎么办
客户机并不知道这一点,因此,它自然会不断地向服务器发送请求。这是不理想的&浪费资源。客户机的过度拉取有可能导致服务器宕机
HTTP PUSH
为了解决这个问题,我们有基于HTTP PUSH的机制。在这种机制中,客户端向服务器发送对特定信息的请求,这只是第一次,在这之后,只要新的更新可用,服务器就会不断地向客户端推送更新。
客户端不需要担心向服务器发送数据请求。这节省了大量的网络带宽,并逐级降低了服务器上的负载。
这也被称为Callback。客户端打电话给服务器询问信息。服务器回应:“嘿!!”我现在还没有这方面的信息,但是我一有时间就会给你打电话。
一个非常常见的例子就是用户通知。我们今天几乎在所有的网络应用中都有它们。每当后台发生事件时,我们都会得到通知
客户端使用AJAX(异步JavaScript & XML)以HTTP Pull机制向服务器发送请求。基于HTTP Push的机制涉及多种技术,例如
- Ajax长轮询
- Web Sockets
- HTML5 event source
- 消息队列
- streaming over HTTP
HTTP Pull - Polling with Ajax
有两种方法可以从服务器中 pulling/fetching 数据。
- 首先通过触发 sending an** HTTP GET请求**发送到服务器一个事件,例如通过单击网页上的按钮或任何其他元素。
- 另一种是使用AJAX在不需要人工干预的情况下,定期动态获取数据。
AJAX代表异步JavaScript和XML。它的名字说明了一切,它是用来添加异步行为的网页。
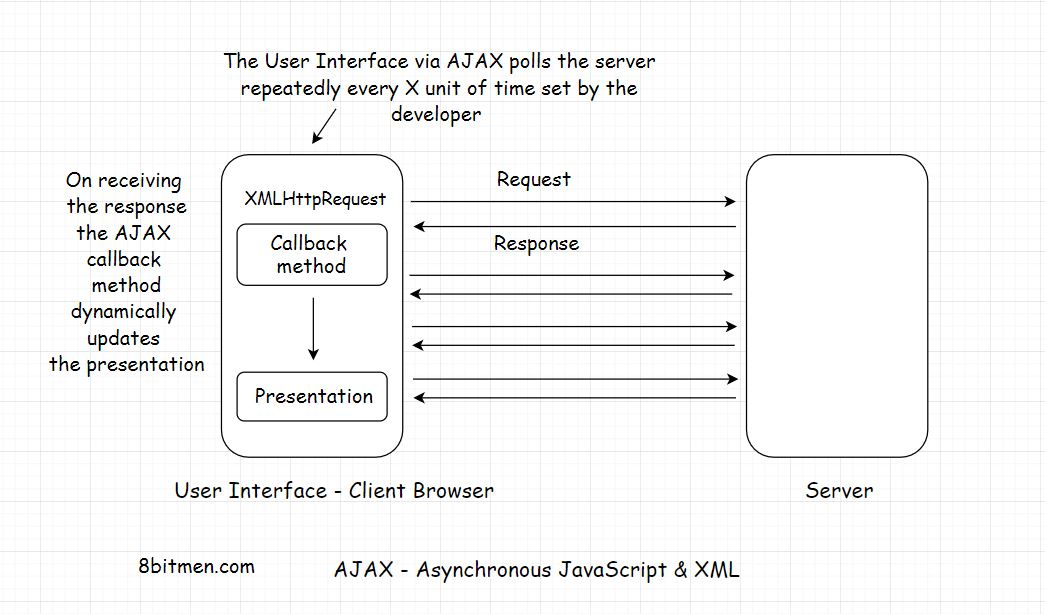
正如我们在上面的插图中看到的,不是每次点击按钮都手动请求数据。AJAX使我们能够通过在规定的时间间隔内一次又一次地自动发送请求来从服务器获取更新后的数据
在接收到更新后,web页面的特定部分会通过回调方法动态更新。我们在新闻和体育网站上经常看到这种行为,更新的事件信息会动态地显示在页面上,而不需要重新加载。
AJAX使用XMLHttpRequest对象将请求发送到内置在浏览器中的服务器,并使用JavaScript更新HTML DOM
AJAX通常与Jquery框架一起用于在UI上实现异步行为。
这种定期从服务器请求信息的动态技术称为轮询。
HTTP Push
Live yo live(TTL)
在常规的客户机-服务器通信(即HTTP PULL)中,每个请求都有一个生存时间(Time to Live, TTL)。它可能是30到60秒,根据浏览器的不同而不同。
如果客户端在TTL内没有收到来自服务器的响应,浏览器将终止连接&客户端必须重新发送请求,希望它能在这次TTL结束之前收到来自服务器的数据
打开的连接会消耗资源&服务器在某个时间点上可以处理的打开的连接数量是有限制的。如果连接不关闭,并引入新的连接,随着时间的推移,服务器将耗尽内存。因此,TTL用于客户机-服务器通信。
但是,如果我们确定响应将花费比浏览器设置的TTL更长时间呢
Persistent Connection 持续连接
持久连接是指客户端和服务器之间的网络连接,它对进一步的请求和响应保持开放,而不是在一次通信后关闭。
在本例中,我们需要客户端和服务器之间的持久连接。
它有助于客户端和客户端之间的HTTP推送的通信服务器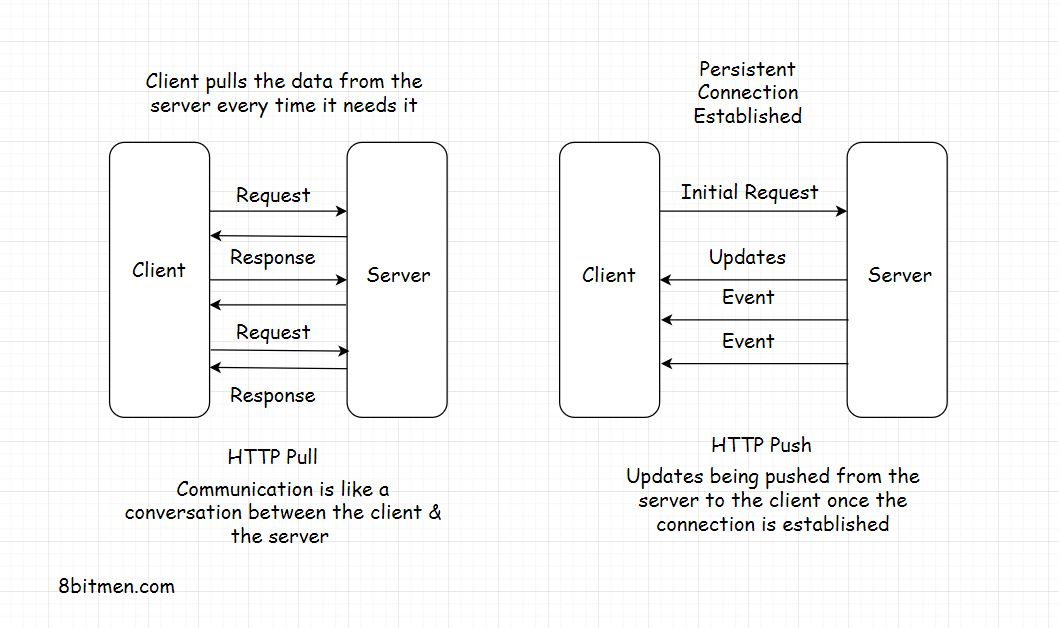
Heartbeat Interceptors 心跳拦截器
现在您可能想知道,如果浏览器每隔X秒就终止打开的到服务器的连接,那么持久连接是如何实现的
客户端和服务器之间的连接在Heartbeat Interceptors的帮助下保持打开状态
这些只是客户机和服务器之间的空白请求响应,以防止浏览器终止连接。
与HTTP Pull行为相比,持久连接消耗了大量的资源。但是在一些用例中,建立持久连接对应用程序的特性至关重要。
资源密集
例如,与常规的web应用程序相比,基于浏览器的多人游戏在特定时间内具有相当多的请求-响应活动。
从用户体验的角度来看,它倾向于在客户机和服务器之间建立一个持久的连接。
长连接可以通过多种技术实现,如Ajax长轮询、Web Sockets、服务器发送事件等。
HTTP Push-Based Technologies 基于 HTTP PUSH 的技术
Web Sockets
当我们需要一个持久的双向低延迟的数据流从客户端到服务器和返回时,Web Socket连接是理想的选择。
这类应用的典型用例是即时通讯、聊天应用、实时社交流和基于浏览器的大型多人游戏,与常规web应用相比,这些游戏具有大量的读写功能
使用Web Sockets,我们可以让客户端-服务器连接保持打开状态,只要我们想
bi-directional data?继续使用Web Sockets。还有一件事,Web Sockets技术不能在HTTP上工作。它在TCP上运行。服务器和客户端都应该支持web sockets,否则它将无法工作。
WebSocket API和引入WebSocket将socket引入Web是进一步阅读Web socket的很好的资源
AJAX – Long Polling
长轮询介于Ajax和Web Sockets之间。在这种技术中,服务器不会立即返回响应,而是保存响应,直到它找到要发送给客户端的更新。
与轮询相比,长轮询中的连接保持打开的时间更长一些。服务器不会返回空响应。如果连接断开,客户端必须重新建立与服务器的连接.
与常规轮询机制相比,使用这种技术的好处是,从客户机发送到服务器的请求数量要少得多。这减少了大量的网络带宽消耗。
长轮询可以用在简单的异步数据获取用例中,当你不想时不时地轮询服务器时。
HTML5 Event Source API & Server Sent Events
Server-Sent Events实现采用了一些不同的方法。当更新可用时,服务器将自动将数据推送给客户机,而不是客户机轮询数据。从服务器传入的消息被视为Events。
通过这种方法,一旦客户端建立了与初始请求的连接,服务器就可以向客户端发起数据传输
这有助于消除大量的空白请求-响应周期,从而逐级降低带宽消耗。
为了实现服务器发送的事件,后端语言应该支持技术&在UI上HTML5事件源API用于接收来自后端数据。
这里需要注意的重要一点是,一旦客户端与服务器建立了连接,数据流就只有一个方向,即从服务器到客户端。
SSE是理想的场景,如Twitter的实时feed,在UI上显示股票报价,实时通知等
This is a good resource for further reading on SSE
Streaming Over HTTP
Streaming Over HTTP 理想的情况下,我们需要流的情况下,我们需要通过HTTP将大数据分成小块。这是可能的HTML5 & JavaScript Streaming API。
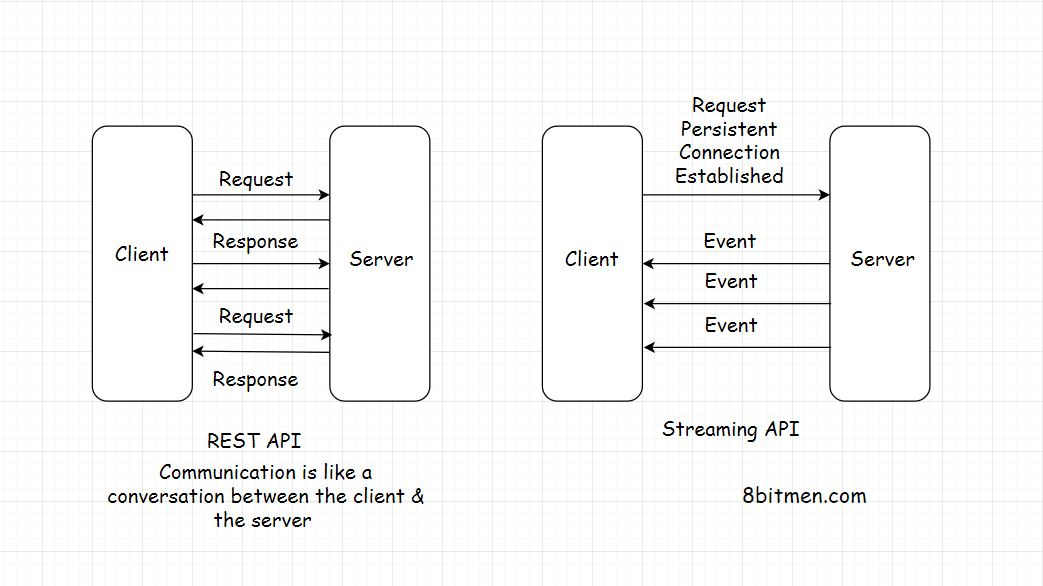
该技术主要用于流媒体内容,如大型图像、视频等,通过HTTP。
因此,我们可以观看部分下载的视频,因为它继续下载,通过播放下载的块在客户端上
为了流数据,客户端和服务器都同意遵循一些流设置。这有助于他们在HTTP请求-响应模型中确定流的开始和结束时间
You can go through this resource for further reading on Stream API
每一种技术都有特定的用例,Ajax通过定期轮询服务器来动态更新网页。
长轮询(Long polling)的连接打开时间略长于轮询机制。
Web Sockets具有双向的数据流,而SSE促进了从服务器到客户端的数据流
Streaming over HTTP有助于大型对象(如多媒体文件)的流媒体。
Scalability
我很确定,在软件开发领域,您已经多次遇到这个词。可伸缩性。它是什么?为什么它如此重要?为什么每个人都在谈论它?扩展系统很重要吗?当你的应用或平台出现显著的流量增长时,你的计划或应急措施是什么.例如:在web应用程序、分布式系统或云计算环境中,可伸缩性意味着什么?
什么可伸缩性
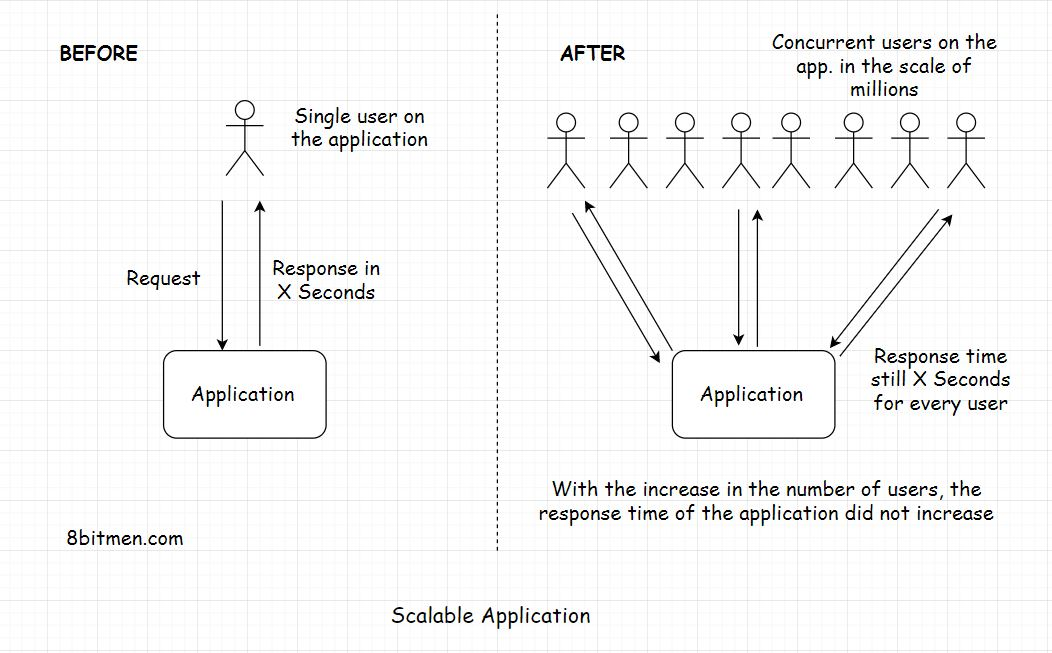
可伸缩性意味着应用程序能够在不牺牲延迟的情况下处理和承受增加的工作负载
例如,如果你的应用程序需要x秒来响应用户的请求。在你的应用程序上,响应每一个并发的用户请求需要相同的x秒。
应用程序的后端基础设施不应该在一百万并发请求的负载下崩溃。在承受较大的流量负载时,它应该具有良好的可伸缩性,并且应该保持系统的延迟
Latency 延迟
延迟是系统响应用户请求所需的时间。假设你向一个应用程序发送一个请求来获取一张图片&系统需要2秒的时间来响应你的请求。系统的延迟时间为2秒
最小延迟是有效的软件系统所追求的。无论系统上的流量负载增加多少,延迟都不应该增加。这就是可伸缩性。
如果延迟保持不变,我们可以说,应用程序可以随着负载的增加而很好地扩展,并且具有高度的可伸缩性
让我们从Big-O符号的角度来考虑可伸缩性。理想情况下,系统或算法的复杂度应该是O(1),它是一个常数时间,就像键值数据库一样
一个复杂度为O(n²)的程序,其中n是数据集的大小,是不可伸缩的。随着数据集的增加,系统将需要更多的计算能力来处理这些任务。
#### Measuring Latency测量延迟
延迟是由用户在网站上采取的动作之间的时间差来衡量的,它可以是一个事件,比如点击一个按钮,以及系统对该事件的反应。
这个延迟一般分为两部分:
- 网络延迟
- 应用程序的延迟
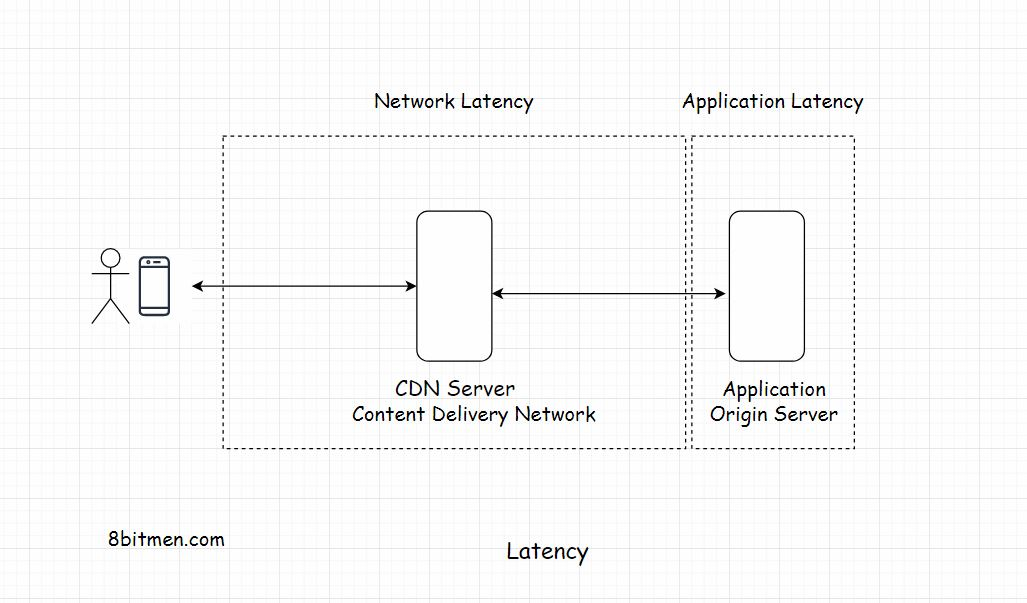
Network Latency 网络延迟
网络延迟是指网络将一个数据包从a点发送到b点所花费的时间。网络应该有足够的效率来处理网站上增加的流量负载。为了减少网络延迟,企业使用CDN,并试图在全球各地部署服务器,尽可能接近最终用户。
Application Latency应用程序延迟
应用程序延迟是应用程序处理用户请求所需的时间。有很多方法可以减少应用程序延迟。第一步是在应用程序上运行压力和负载测试,并扫描导致系统整体变慢的瓶颈。
为什么低延迟对于在线服务如此重要?
延迟在决定在线业务是否赢得或失去客户方面起着重要作用。没有人喜欢在网站上等待回复。有一个众所周知的说法,如果你想测试一个人的耐心,给他一个缓慢的互联网连接.
如果访问者在规定的时间内得到回复,那就太好了,否则他就会转到另一个网站去.
大量的市场研究表明,应用程序的高延迟是客户离开网站的一个重要因素。如果涉及到资金,零延迟是企业想要的,只有在这是可能的情况下。
想想大型多人在线MMO游戏,游戏内事件的轻微延迟会破坏整个游戏体验。一个拥有高延迟网络连接的玩家将会有一个较慢的反应时间,尽管他拥有一个竞技场中所有玩家的最佳反应时间.
算法交易服务需要在几毫秒内处理事件。金融科技公司拥有运行低延迟交易的专用网络。普通的网络无法做到这一点。
华为和Hibernia Atlantic公司在2011年开始铺设横跨大西洋的伦敦和纽约之间的光纤连接电缆,这一事实让我们认识到低延迟的重要性。3亿美元,为交易员节省了6毫秒的延迟。
Types Of Scalability
应用程序的扩展性需要坚实的计算能力。这些服务器应该足够强大,能够处理增加的流量负载
横向扩展(水平扩展)
水平扩展,也称为向外扩展,意味着向现有硬件资源池添加更多的硬件。这增加了整个系统的计算能力
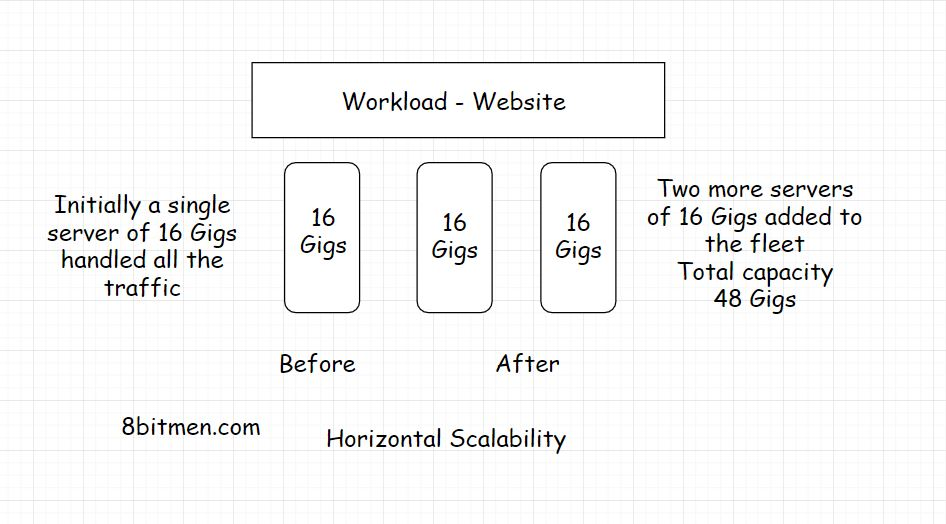
现在,增加的流量流入可以很容易地处理增加的计算能力&假设我们有无限的资源,我们可以水平地扩展多少实际上没有限制。我们可以不断增加服务器,建立一个又一个数据中心.水平扩展也为我们提供了实时动态扩展的能力,随着我们网站的流量在一段时间内的增加和减少,而不是垂直扩展,这需要预先规划和规定的时间来完成。
垂直扩展
垂直扩展意味着为服务器添加更强大的功能。让我们假设你的应用由一个拥有16g内存的服务器托管。为了处理增加的负载,可以将RAM增加到32g。您已经对服务器进行了垂直伸缩
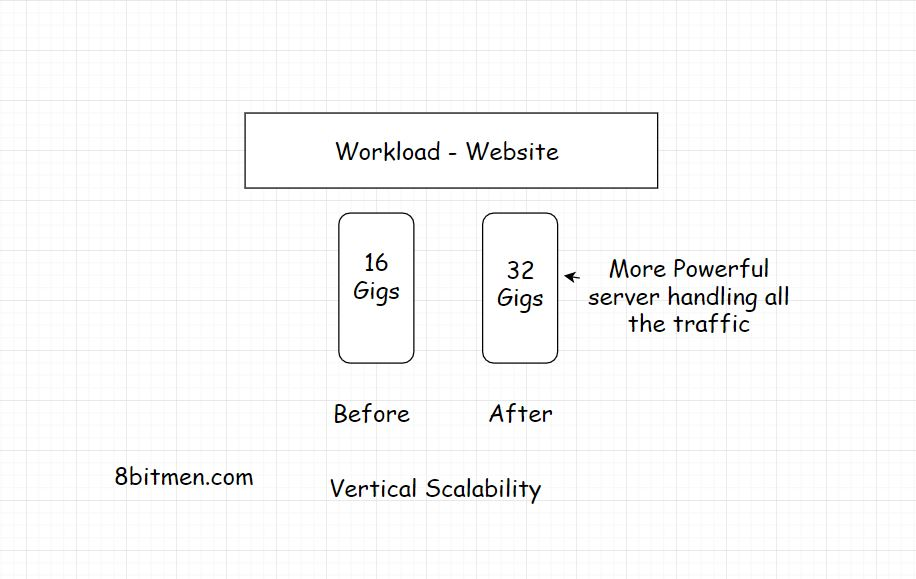
理想情况下,当应用的流量开始增长时,第一步应该是垂直扩展。垂直扩展也称为向上扩展。但在垂直扩展时,我们能做的也就这么多了。对于一台服务器,我们所能增加的容量是有限的
在这种类型的扩展中,我们增加了运行应用的硬件的能力。这是最简单的扩展方式,因为它不需要任何代码重构,不需要任何复杂的配置和其他东西。我将在下一课中进一步讨论,当我们水平扩展应用程序时,为什么需要代码重构.
#### 云弹性Cloud Elasticity
云计算在行业中如此流行的最大原因是它能够动态地向上和向下扩展。只使用和支付网站所需资源的能力成为了一种趋势,原因显而易见。如果站点有一个沉重的流量流入更多的服务器节点被添加&当它不动态添加的节点被删除。
这种方法每天为企业节省了大量的钱。这种方法也被称为云弹性。它表明了对原始基础设施计算能力的拉伸和回归。
在后台有多个服务器节点也可以帮助网站保持在线,即使一些服务器节点崩溃。这就是所谓的高可用性。我们将在接下来的课程中讲到。
适合自己应用的扩展方法
#### 垂直和水平扩展的利与弊代码怎么样?
- 垂直扩展比水平扩展更简单,因为我们不需要修改代码,也不需要做任何复杂的分布式系统配置。与管理分布式环境相比,它需要更少的管理、监视和管理工作。
- 垂直扩展的一个主要缺点是可用性风险。服务器很强大,但数量很少,总有宕机的风险&整个网站离线,当系统水平扩展时不会发生这种情况。它变得更加可用。
当需要在多台机器上运行时,为什么代码需要更改?
如果您需要在分布式环境中运行代码,那么它需要是无状态的。代码中不应该有任何状态。这是什么意思呢
no static instance in the class. static instance (静态实例)保存在了应用程序数据,如果Aparticular Server下线,所有静态数据/状态都会丢失。该应用程序留在了一个状态不一致。
今天的开发团队从一开始就采用分布式微服务架构&工作负载应该部署在云上。因此,工作负载(workloads)本质上是动态水平扩展的。
水平扩展的好处包括不限制增加硬件容量。随着节点和数据中心在全球各地建立,数据可以跨不同的地理区域复制.
哪种可扩展性方法适合你的应用
- 如果你的应用程序是一个实用程序或工具,预计接收最小的一致流量( consistent traffic),它可能不是关键任务。例如,一个组织的内部工具或类似的东西。
- 当您知道流量负载不会显著增加时,可以继续进行垂直扩展.一台服务器就足够管理流量了.
- 如果你的应用是面向公众的社交应用,如社交网络、健身应用或类似的应用,那么它的流量预计将在不久的将来呈指数增长。高可用性和水平可伸缩性对您都很重要.构建并将其部署到云上&从一开始就要牢记水平可伸缩性。
Primary Bottlenecks that Hurt the Scalability Of Our Application
影响应用可扩展性的主要瓶颈
数据库
考虑一下,我们的应用程序看起来是架构良好的。一切看起来不错。工作负载在多个节点上运行,并具有水平扩展的能力。但是,数据库是一个糟糕的单一整体,只有一台服务器负责处理来自工作负载的所有服务器节点的数据请求。
这种情况是一个瓶颈。服务器节点工作得很好,在一个时间点上有效地处理数百万个请求,但这些请求的响应时间和应用程序的延迟非常高,因为只有一个数据库。它能处理的也就这么多了.
就像工作负载可伸缩性一样,数据库也需要良好的可伸缩性。合理利用数据库分区、分片,使用多个数据库服务器使模块高效。
应用程序架构(Application Architecture)
设计不良的应用程序体系结构可能成为一个主要的瓶颈。
一个常见的架构错误是在需要的地方不使用异步进程和模块,而是将所有进程按顺序调度
例如,如果用户在门户上载下载文档,则诸如发送给用户确认电子邮件的任务,向所有人发送通知等,应该异步地完成上传事件的订阅者/侦听器
这些任务应该转发到消息服务器,而不是顺序地执行所有任务&让用户等待所有任务。
#### 在应用层使用缓存
缓存可以部署在应用程序的几个层&它可以逐级加快响应时间。它拦截到数据库的所有请求,减少了数据库的总体负载。在整个应用程序中竭尽全力地使用缓存,以显著提高速度
#### 优化配置与设置负载均衡
负载均衡器是我们的应用程序的入口。使用太多或太少会影响我们应用程序的延迟。
不要将业务逻辑添加到数据库
不管别人给出什么理由,我从来都不喜欢添加业务逻辑到数据库。数据库不是存放业务逻辑的地方。它不仅使整个应用程序紧密耦合。它给它增加了不必要的负荷。
想象一下,当迁移到一个不同的数据库时,需要重构多少代码。
没有选择正确的数据
选择正确的数据库技术对企业来说至关重要。需要事务和强一致性?选择一个关系数据库。如果可以的话没有强一致性而需要水平可伸缩性的情况下选择一个NoSQL数据库。
#### 在代码级别
这并不令人惊讶,但是低效率和糟糕的代码有可能破坏生产环境中的整个服务,其中包括:
- 使用不必要的循环,嵌套环。
- 写得紧密耦合的代码。
- 在编写代码时不关注大o复杂性。是准备在生产中做了很多消防措施。
如何改进和测试应用程序的可伸缩性
下面是一些优化web应用程序性能的常见策略和最佳策略。如果应用程序是性能优化的,它可以承受更多的流量负载和更少的资源消耗,而不是一个应用程序的性能优化。
现在你可能会想,为什么我要谈论性能,而不是可伸缩性.应用程序的性能与可伸缩性直接成正比。如果一个应用程序的性能不好,那么它肯定不能很好地扩展。这些最佳实践甚至可以在对应用程序进行实际的预生产测试之前实现。
##### 优化应用程序的性能,使其能够更好地伸缩
Profiling
运行应用程序分析程序,代码分析程序。查看哪些进程花费的时间太长,消耗了太多的资源。找出瓶颈。摆脱他们。
分析是对代码的动态分析。它帮助我们测量我们的代码的空间和时间复杂性,并使我们能够找出问题,如并发错误,内存错误和程序的健壮性和安全性。这个Wikipedia资源包含一个行业中使用的性能分析工具的很好的列表
Caching
明智的缓存。缓存无处不在。缓存所有静态内容。只有在确实需要时才访问数据库。尝试从缓存处理所有读请求。使用透写缓存。
**CDN (Content Delivery Network) **
使用CDN。由于来自请求用户的数据很接近,使用CDN进一步减少了应用程序的延迟。
Data Compression
压缩数据。使用apt压缩算法压缩数据。以压缩格式存储数据。由于压缩数据占用的带宽更少,因此客户端下载数据的速度会更快。
避免不必要的客户端服务器请求( Avoid Unnecessary Client Server Requests )
避免客户端和服务器之间不必要的往返。尝试将多个请求合并到一个请求中。对于应用程序的性能,这些是我们应该记住的一些事情。
Testing the Scalability Of Our Application(测试应用程序的可伸缩性)
一旦我们完成了应用程序的基本性能测试,就该进行容量规划、提供适当数量的硬件和计算能力了。
测试应用程序可伸缩性的正确方法在很大程度上取决于我们系统的设计。没有明确的公式。测试可以在硬件和软件两级执行。不同的服务和组件需要单独和集体进行测试.
在可扩展性测试中,会考虑不同的系统参数,如CPU使用情况、网络带宽消耗、吞吐量、在规定时间内处理的请求数、延迟、程序内存使用情况、系统在重负载下的最终用户体验等。
在这个测试阶段,模拟流量被路由到系统,以研究系统在重负载下如何工作,应用程序在重负载下如何扩展。意外事件是为不可预见的情况而计划的。
根据预期的流量,提供适当的硬件和计算能力,以在一定的缓冲区内平稳地处理流量。
在应用程序上运行了几个负载和压力测试。如果您使用的是Java生态系统,像JMeter这样的工具非常适合在应用程序上运行并发用户测试。有很多基于云的测试工具可以帮助我们通过点击几下鼠标来模拟测试场景。
企业一直在测试可伸缩性,以使他们的系统为处理流量激增做好准备。如果是体育网站,就要为运动会做好准备;如果是电子商务网站,就要为节日做好准备。
High Availability(高可用)
高可用性计算基础设施是当今计算行业的标准。更重要的是,当涉及到云平台时,它是使运行在其上的工作负载具有高可用性的关键特性。
什么是高可用
高可用性(也称为HA)是系统保持在线的能力,尽管在基础设施级别上出现了实时故障。
高可用性确保服务的正常运行时间比正常时间长得多。它提高了系统的可靠性,确保最小停机时间。
高可用性系统的唯一任务是保持在线和保持联系。一个非常基本的例子是有备用发电机,以确保在任何停电情况下持续供电。
在行业中,HA通常以百分比表示。例如,当系统处于99.99999%的高可用状态时,这仅仅意味着服务将启动总主机时间的99.99999%。您可能经常在云平台的SLA(服务水平协议)中看到这一点
高可用性对在线服务有多重要
如果社交应用出现一小段时间的下滑,那么它可能不会对商业产生太大的影响。然而,有些关键任务系统,如飞机系统、航天器、采矿机、医院服务器、金融股票市场系统,在任何时候都无法承受崩溃。毕竟,生命依赖于它。
关键任务系统的顺利运作依赖于持续与其网络/服务器的连接。这些实例没有超级可用的基础设施就无法做到。
此外,没有任何服务愿意宕机,不管它是否苛刻。
为了满足高可用性的需求,系统被设计成容错的,它们的组件是冗余的。
系统故障原因分析
在深入研究高可用性系统设计、容错和冗余之前。我将首先讨论系统失败的常见原因。
Software Crashes软件崩溃
我相信你对软件崩溃很熟悉。应用程序总是崩溃的,无论是在手机上还是在台式机上。腐败的软件文件。还记得蓝屏蓝屏的死亡窗口吗?操作系统崩溃,内存占用,进程无响应。同样,运行在云节点上的软件也会不可预测地崩溃,并导致整个节点瘫痪。
Hardware Failures硬件故障
系统故障的另一个原因是硬件崩溃。CPU过载,RAM,硬盘故障,节点故障。网络中断。
Human Errors人因失误
这是系统故障的最大原因。有缺陷的配置。谷歌犯了一个小小的网络配置错误,导致日本几乎一半的互联网瘫痪。这是一篇有趣的文章。
Planned Downtime计划停机
除了计划外的崩溃,还有计划内的停机时间,包括日常维护操作、软件补丁、硬件升级等。
这些是导致系统故障的主要原因,现在让我们讨论如何设计高可用性系统来克服这些系统停机的场景。
Fault Tolerance(容错)
有几种方法可以实现HA。其中最重要的是使系统具有容错能力。
什么是容错
容错是系统在遭受打击后仍能正常运行的能力
系统配备了容错系统来处理故障。容错是设计生命关键系统的基本要素。
几个实例/节点,其中几个,运行服务脱机且一直反弹。在这些内部故障的情况下,系统可以降低水平工作,但它不会完全下线。
系统容错的一个非常基本的例子是社交网络应用程序。在后台节点故障的情况下,app的一些服务,如图片上传、点赞等可能会停止工作。但是整个应用程序还是会运行的。这种方法在技术上也被称为失败软件(Fail Soft)
设计高可用容错服务体系结构
为了在应用程序级别实现高可用性,整个大规模服务在体系结构上被分解为更小的松散耦合的服务,称为微服务(micro-services)。
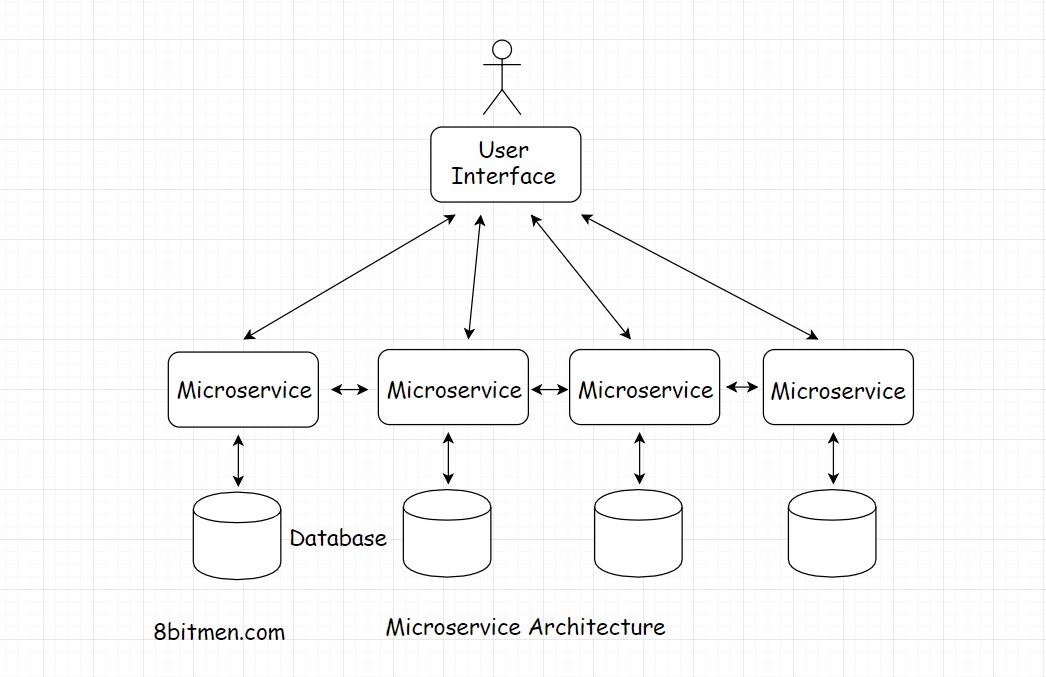
将一个庞大的庞然大物分割成几个微服务有很多好处,正如它所提供的那样:
- 更轻松的管理
- 更容易开发
- 轻松添加新功能
- 易于维护
- 高可用性
每一个微服务都承担着运行应用程序不同功能的责任,比如图片上传、评论、即时消息等.
因此,即使一些服务下线,应用程序作为一个整体仍然是可用的
redundancy(冗余)
Redundancy Active-Passive HA Mode(主备冗余HA模式)
冗余是复制组件或实例,让它们处于备用状态,以便在活动实例宕机时接管。这是一种故障安全的备份机制。
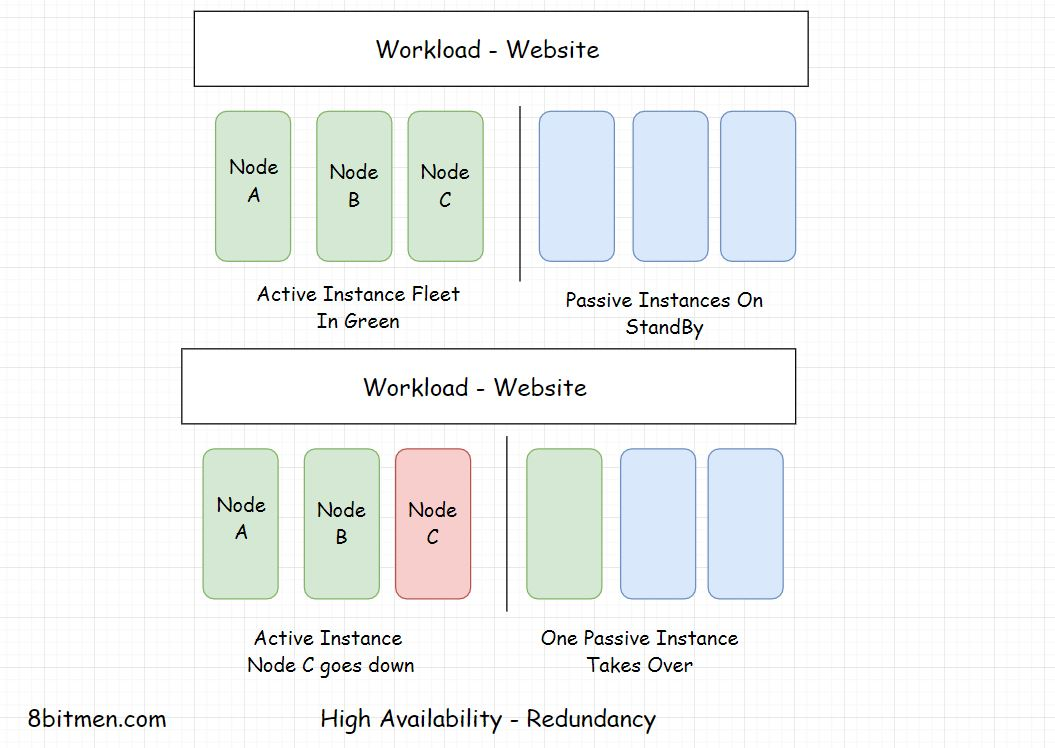
在上图中,您可以看到实例处于活动状态&处于备用状态。在任何活动实例宕机的情况下,备用实例将接管
这种方法也称为主备HA模式。一组初始节点是活动的,一组冗余节点是被动的,处于备用状态。在出现故障时,主动节点会被被动节点替换。
像GPS、飞机、通信卫星这样的系统都是零停机的。这些系统的可用性是通过使组件冗余来保证的。
Getting Rid Of Single Points Of Failure(消除单点故障)
分布式系统之所以如此流行,完全是因为有了它们,我们可以摆脱单片架构中存在的单点故障。
大量的分布式节点相互协作,以实现单一的同步应用程序状态。
当部署了这么多冗余节点时,系统中就不会出现单点故障。如果某个节点出现故障,冗余节点会代替它。因此,整个系统没有受到影响
应用程序级别的单点故障意味着瓶颈。我们应该在性能测试中发现瓶颈,并尽快摆脱它们。
##### Monitoring & Automation
系统应该实时监控,以检测任何瓶颈或单点故障。自动化使实例能够在没有任何人工干预的情况下进行自我恢复。它给了这些例子自愈的力量。
此外,系统变得足够智能,可以根据需求动态地添加或删除实例
由于最常见的故障原因是人为错误,自动化有助于在很大程度上减少故障。
Replication Active-Active HA Mode(复制双活HA模式)
复制意味着让许多相似的节点一起运行工作负载。不存在备用或被动实例。当一个或几个节点宕机时,剩余的节点将承担服务的负载。可以将此视为负载平衡
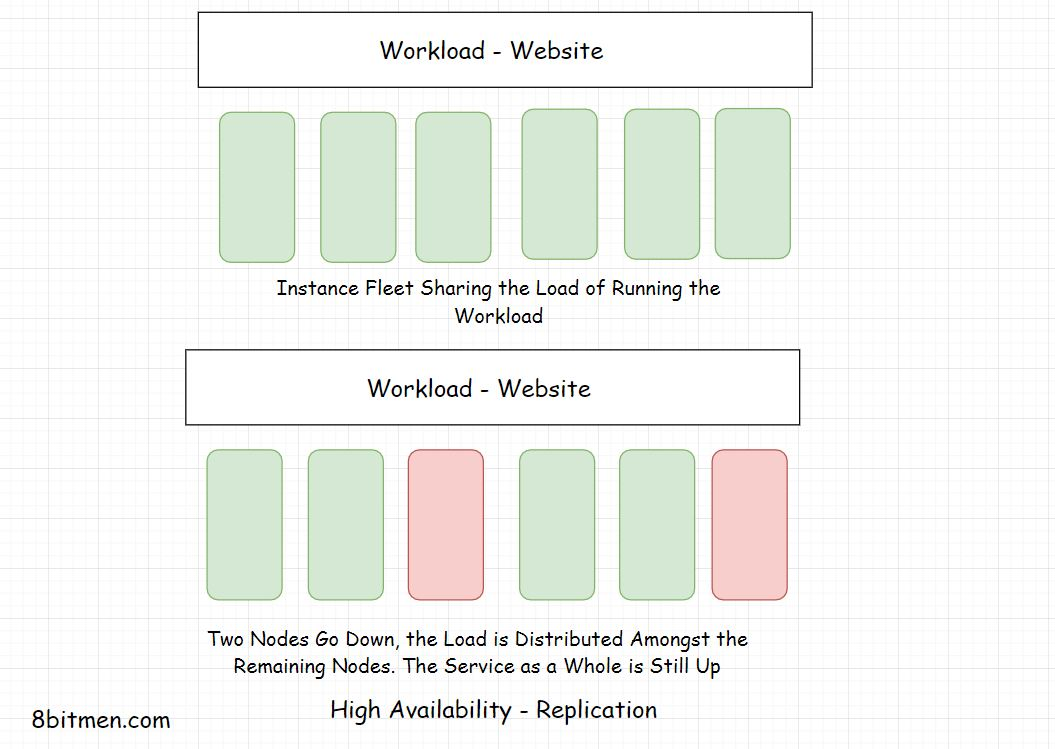
负载平衡。这种方法也称为Active Active High Availability模式。在这种方法中,系统的所有组件在任何时间点都是活动的。
Geographical Distribution of Workload工作量的地域分布
作为自然灾害、数据中心区域停电和其他大规模故障的应急措施,工作负载分布在世界各地不同地理区域的不同数据中心。
这避免了数据中心上下文中的单点故障。此外,由于数据与用户的距离较近,延迟也大大减少。
所有高可用容错设计决策都是由系统的重要性决定的。组件失败的几率是多少?等。
企业经常使用多云平台来部署他们的工作负载,以确保进一步的可用性。如果一家云服务提供商出了问题,他们还有另一家可以恢复
High Availability Clustering(高可用的集群)
高可用性集群也称为故障转移集群,它包含一组相互连接运行的节点,以确保服务的高可用性。
集群中的节点通过称为Heartbeat的私有网络连接,该网络持续监视集群中每个节点的健康状况和状态。
集群中所有节点的单一状态是通过共享的分布式内存和分布式协调服务实现的,比如Zookeeper
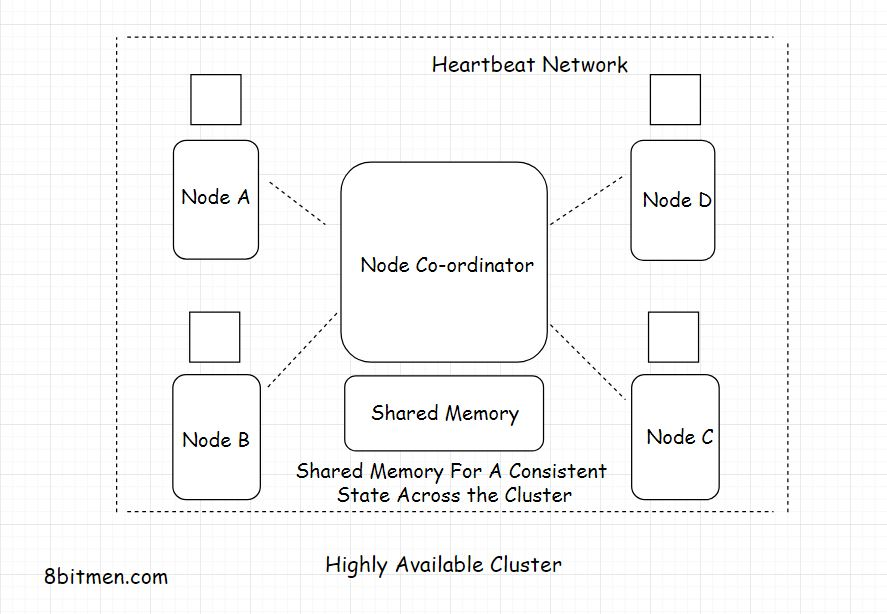
为确保可用性,HA集群使用多种技术,如磁盘,镜像/ RAID冗余独立磁盘阵列,网络连接冗余,电力冗余等。网络连接是冗余的,所以如果主网络出现故障,备用网络就会接管。
多个HA集群一起运行在一个地理区域,确保最小停机时间和持续服务。
monolithic architecture(单片应用结构)
如果应用程序将整个应用程序代码包含在一个代码库中,则该应用程序具有单一的体系结构。
单片应用是一种独立的、单层的软件应用,与微服务体系结构不同,微服务体系结构中不同的模块负责运行应用程序中各自的任务和特性
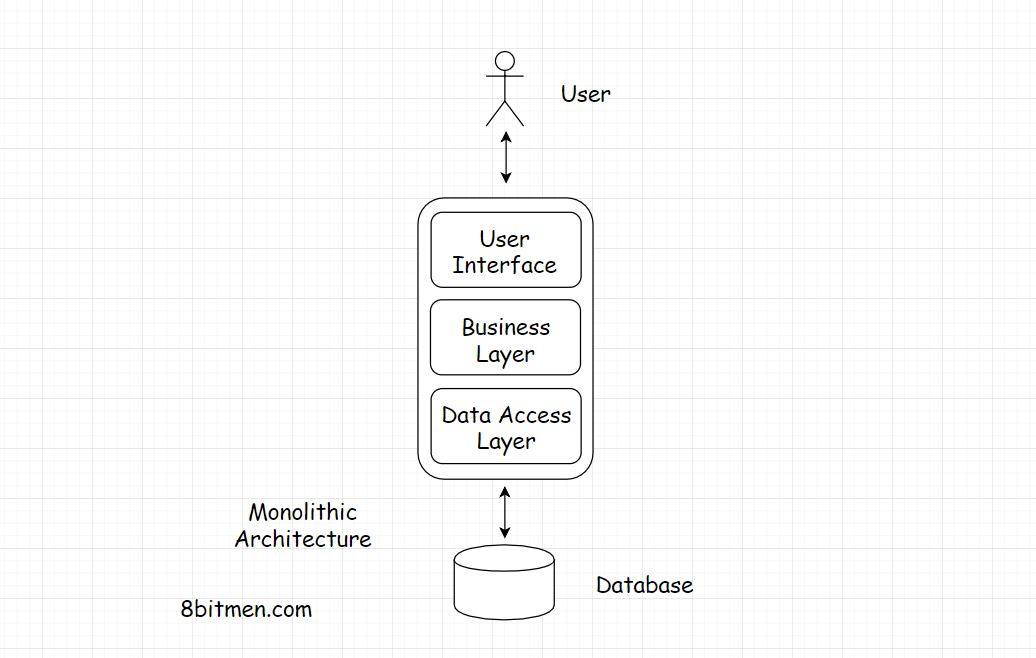
在一个单一的web应用程序中,应用程序、UI、业务、数据访问等所有不同的层都在同一个代码库中。我们有控制器(Controller),然后是服务层(service),类接口的实现,业务逻辑放在对象域模型中,在服务中服务中的一点,业务逻辑和存储库/ DAO [数据访问对象]一起进行整合.
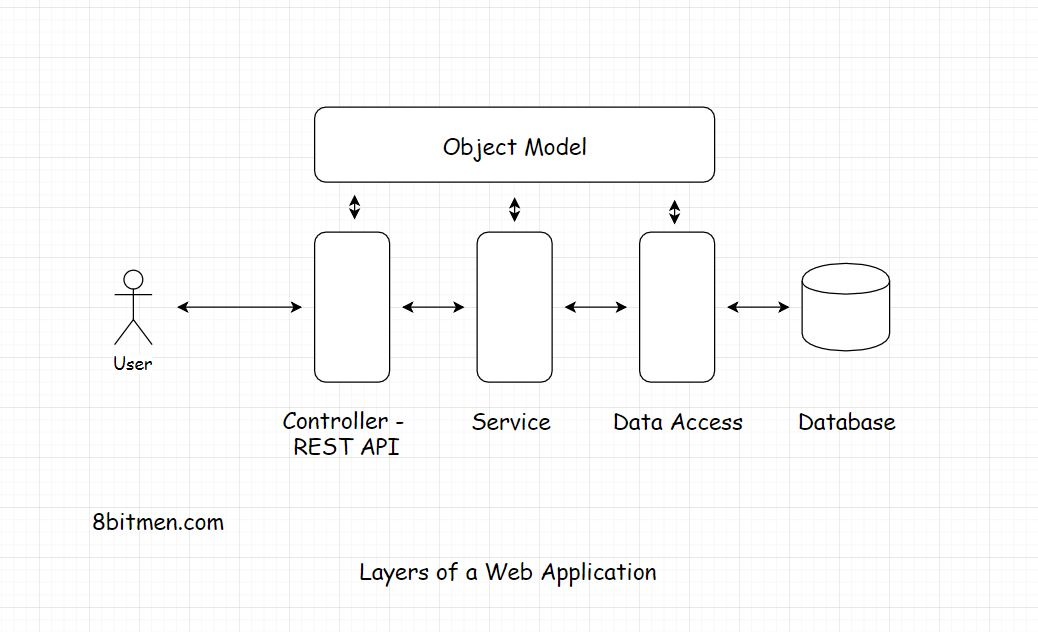
与微服务架构相比,单块应用更容易构建、测试和部署。有时候,在业务的初始阶段,团队会选择继续使用单片架构,然后打算扩展到分布式的微服务架构.
在目前的计算环境中,应用程序都是在云上构建和部署的。一个明智的决定是,从一开始就选择松散耦合的无状态微服务体系结构,如果您预计未来的发展速度会相当快的话。
因为重写东西是有代价的。在紧密耦合的架构中剥离一些东西和重写一些东西需要大量的资源和时间。
另一方面,如果你的需求很简单,为什么要写一个微服务体系结构呢?同时运行不同的模块并不是在公园里散步。
Pros Of Monolithic Architecture(单片架构的优点)
Simplicity
单片式应用程序开发、测试、部署、监控和管理都很简单,因为所有的东西都驻留在一个存储库中。处理不同的组件、让它们彼此协同工作、监控几个不同的组件和材料并不复杂。事情很简单。
单片架构的缺点
Continuous Deployment持续部署
对于单片应用来说,连续部署是一件痛苦的事情,因为即使是连续部署,也需要对整个应用程序进行重新部署。
regression testing回归测试
这样做的缺点是,在部署完成后,我们需要对整个应用程序进行彻底的回归测试,因为各层之间是紧密耦合的。一个层中的变化会显著影响其他层。
Single Points Of Failure单点失败
单片应用程序只有一个故障点。如果任何一个层有错误,它有可能使整个应用程序崩溃。
Scalability Issues伸缩问题
灵活性和可伸缩性在单一应用中是一个挑战,因为在一个层面上的改变通常需要在所有层面上进行改变和测试。随着代码大小的增加,事情可能会变得有点棘手。
Cannot Leverage Heterogeneous Technologies不能利用异构技术
由于兼容性问题,使用单一体系结构构建复杂的应用程序非常困难,因为在单个代码库中使用异构技术非常困难。在一个代码库中同时使用Java和NodeJS是很棘手的.
Not Cloud-Ready, Hold State不是云就绪,是保持状态
通常,单片应用程序没有云准备好,因为它们在静态变量中保持状态。一个应用程序要想成为云原生应用,要想在云上平稳地工作和一致,就必须是分布式的和无状态的
什么时候应该选择单片架构
单片式应用程序最适合需求非常简单的用例,应用程序被期望处理有限的流量。这方面的一个例子是一个组织的内部税务计算应用程序或类似的开放公共工具。
在这些用例中,企业确定用户基础和流量不会随着时间的推移呈指数级增长.
也有开发团队决定从单片架构开始,然后扩展到分布式微服务架构的例子.
这有助于他们根据需要一步一步地处理应用程序的复杂性。这正是LinkedIn所做的
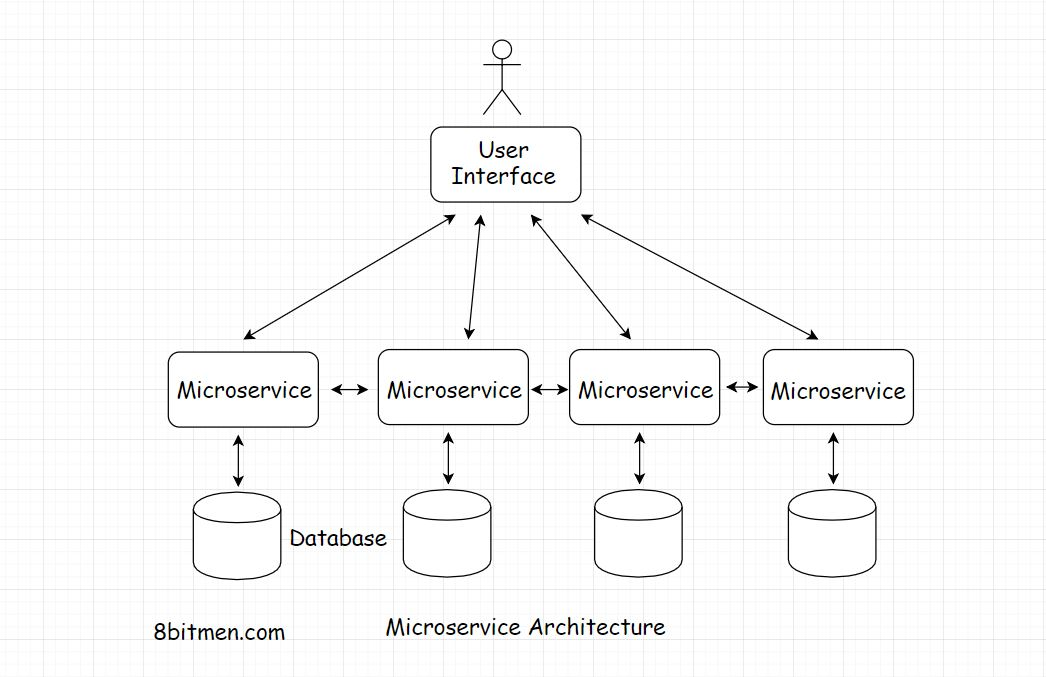
Microservice architecture
在微服务体系结构中,不同的功能/任务被分成将相应的 模块/codebbases 分开,彼此整体形成大型服务
还记得单一责任和关注点分离原则吗?这两个原则都应用于微服务体系结构中
想象一下在一个存储库中容纳每个特性。事情会有多复杂?这将是一场维护噩梦。
此外,由于项目很大,它将由几个不同的团队管理。当模块是独立的时,它们可以被分配到各自的团队中,从而使开发过程更加顺利。
我提到可扩展性了吗?为了扩大规模,我们需要把东西分开。当我们无法进一步扩大规模时,我们需要扩大规模。微服务体系结构天生就是可伸缩的。
下图代表了一个微服务体系结构
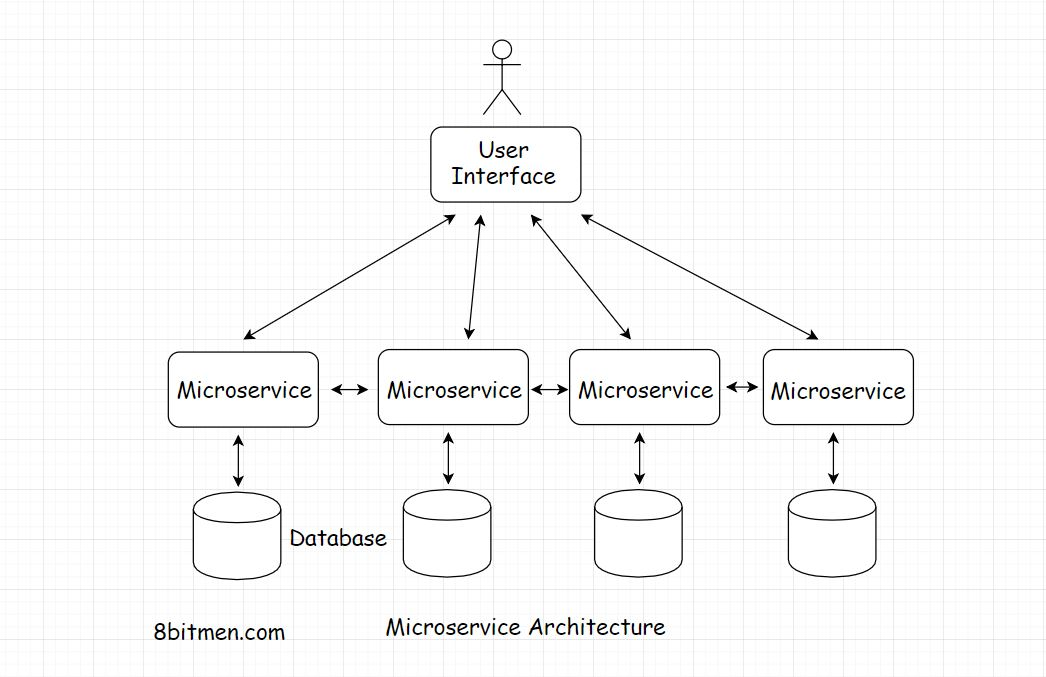
理想情况下,每个服务都有一个独立的数据库,没有单点故障和系统瓶颈。
微服务的优点
No Single Points Of Failure 没有单点故障
由于微服务是松散耦合的体系结构,因此不存在单点故障。即使一些服务中断,应用程序作为一个整体仍然是正常的。
Leverage the Heterogeneous Technologies 利用异构技术
每个组件都通过REST API Gateway接口进行交互。这些组件可以利用多语言持久性体系结构和其他异构技术,如Java、Python、Ruby、NodeJS等
Polyglot持久性是在一个体系结构中同时使用多种数据库类型,如SQL、NoSQL。我将在数据库课中详细讨论它
Independent & Continuous Deployments 独立和持续部署
部署可以是独立的和连续的。我们可以为每一个微服务建立专门的团队,它可以独立扩展而不影响其他服务
##### 微服务的缺点
Complexities In Management管理的复杂性
微服务是一个分布式环境,其中有很多节点一起运行。管理和监控他们变得复杂。我们需要安装额外的组件来管理微服务,比如一个像Apache Zookeeper这样的节点管理器,一个用于监控节点的分布式跟踪服务等等。我们需要更多的技术资源,也许需要一个专门的团队来管理这些服务
No Strong Consistency 没有强烈的一致性
在分布式环境中很难保证强一致性。最终,节点之间的事情是一致的。这种局限性是分布式设计造成的。
When Should You Pick A Microservices Architecture
微服务架构最适合复杂的用例,也最适合那些像社交网络应用一样期待流量在未来呈指数增长的应用。
一个典型的社交网络应用程序有各种各样的组件,如消息,实时聊天,实时视频流,图像上传,喜欢,分享功能等
在一个代码库中编写每个特性,很快就会变得一团糟。
所以,到目前为止,在整体服务和微服务的背景下,我们已经经历了三种方法
- 选择单一架构
- 选择微服务架构
- 从单片架构开始,然后扩展到微服务架构。
我建议,简单一点,彻底理解需求。了解情况,只在你需要的时候做一些事情,并不断迭代地改进代码。这是正确的方法。
Introduction & Types of Data(数据的介绍和类型)
数据库是持久化数据所需的组件。数据可以有多种形式:结构化、非结构化、半结构化和用户状态数据
在深入研究数据库之前,让我们先快速了解一下数据的分类
Structured Data
结构化数据是符合特定结构的数据类型,通常以规范化的方式存储在数据库中。
在处理结构化数据之前,不需要在其上运行任何类型的数据准备逻辑。可以对这类数据进行直接交互
结构化数据的一个例子是存储在数据库行中的客户的个人详细信息。客户id将是整数类型,名称将是带有一定字符限制的字符串类型,等等
所以,有了结构化数据,我们知道我们在处理什么。因为客户名是String类型的,所以不用太担心错误或异常,我们可以在它上面运行String操作。
结构化数据通常由查询语言(如SQL(结构化查询语言))管理。
Unstructured Data
非结构化数据没有明确的结构。它通常是异构类型的数据,包括文本、图像文件、视频、多媒体文件、pdf、Blob对象、word文档、机器生成的数据等。
这类数据在数据分析中经常遇到。在这里,数据从多个来源(如物联网设备、社交网络、门户网站、行业传感器等)流入分析系统
我们不能直接处理非结构化数据。最初的数据是非常原始的,我们必须让它通过一个数据准备阶段,根据一些业务逻辑将其分离,然后在其上运行分析算法
Semi-structured Data(半结构化数据)
半结构化数据是结构化和非结构化数据的混合体。半结构化数据通常以XML或JSON等数据传输格式存储,并根据业务需求进行处理
User state
包含用户状态的数据是用户在网站上执行的活动信息
例如,在浏览一个电子商务网站时,用户会浏览几个产品类别,改变偏好,在价格下降的提醒列表中添加几个产品。
所有这些活动都是用户状态。因此,下次当用户登录时,他可以从上次停止的地方继续。这不会让人觉得你是在重新开始&之前的活动都已经消失了。
存储用户状态提高了浏览体验和业务的转化率。所以,现在我们清楚了不同类型的数据。让我们看看不同类型的数据库。
有多种不同类型的数据库,它们具有特定的用例。为了对数据库领域有一个全面的了解,我们将快速地浏览它们。
Relational Database
这是行业中最常见和最广泛使用的数据库类型。关系数据库保存包含关系的数据。一对一,一对多,多对多,多对一等等。它有一个关系数据模型。SQL是用于与关系数据库交互的主要数据查询语言。MySQL是关系数据库中最流行的例子。好了! !我明白,但什么是关系
Relational
假设你是一个顾客,从网上书店买了五本不同的书。当您在书店上创建一个帐户时,您将被分配一个客户id,例如C1。现在C1[You]链接到5本书B1, B2, B3, B4, B5.
这是一对多的关系。在最简单的形式中,一个表将包含所有客户的详细信息&另一个表将包含库存中的所有产品。客户表中的一行将对应于产品库存表中的多行.
在从数据库中提取id为C1的用户对象时,我们可以通过关系模型轻松地找到C1购买了哪些书
data consistency(数据一致性)
此外,关系数据库还确保以规范化的方式保存数据.在非常简单的术语中,归一化数据意味着一个唯一的数据实体只在一个地方(表)中,它以最简单的原子形式存在,并且不会在整个数据库中传播。
这有助于维护数据的一致性。以后,如果我们想更新数据,我们只在那个地方更新每个取回操作都会得到更新后的数据。
将数据分散到整个数据库的不同表中。我们必须随时更新实体的新值。这很麻烦,而且会变得不一致。
ACID Transactions
除了规范化和一致性,关系数据库也保证了ACID事务
- ACID – Atomicity, Consistency, Integrity, Durability.(原子性、一致性、完整性、持久性)
acid事务意味着系统中的事务发生,例如,一个金融交易,它将完美地执行,而不影响任何其他流程或交易
事务完成后,系统将有一个新的持久一致的状态。或者,如果事务期间发生了任何错误,比如一个小系统故障,整个操作就会回滚
当事务发生时,系统状态a为初始状态,事务结束后系统状态B为最终状态。这两种状态都是一致和持久的。
关系数据库确保系统在任何时候都处于状态A或状态B。没有中间状态。如果有任何故障,系统返回到状态A。如果事务顺利执行,系统就会从状态A过渡到状态B。
#### 什么时候应该选择关系数据库
如果你正在编写一个股票交易、银行或金融应用程序,或者你需要存储大量的关系,例如,在编写一个像Facebook这样的社交网络时。然后,您应该选择一个关系数据库。这是为什么
当你选择关系数据库,你在选择这些东西
Transactions & Data Consistency事务与数据一致性
如果你正在编写一个与金钱或数字有关的软件,那么交易,ACID,数据一致性对你来说是非常重要的
关系数据库在事务和数据一致性方面表现突出。他们遵守ACID规则,已经存在了很长一段时间并且是经过战斗考验的
Large Community 大社区
此外,他们有一个更大的社区。经验丰富的技术工程师很容易找到,你不需要花太多的时间去寻找他们
Storing Relationships存储关系
如果你的数据有很多关系,比如你的哪些朋友住在一个特定的城市?你的哪个朋友已经在你今天打算去的餐厅吃过饭了?等。没有什么比关系数据库更适合存储这类数据了.
关系数据库是用来存储关系的。他们已经尝试和测试,并被行业巨头使用,如Facebook作为主要面向用户的数据库。
Popular Relational Databases流行的关系数据库
行业中使用的一些流行的关系数据库是MySQL——它是一个开源的关系数据库,用C和c++编写,自1995年以来就出现了.
其他的则是Microsoft SQL Server,这是微软用C、c++编写的一种专有的RDBMS。MariaDB, Amazon Aurora,谷歌Cloud SQL等
NoSQL Databases
NoSQL数据库没有SQL,它们更像是为Web 2.0构建的基于json的数据库。它们是为高频读写而构建的,通常需要在社交应用程序中,如Twitter、实时体育应用程序、在线大规模多人游戏等。
NoSQL数据库与关系数据库的区别
现在,一个明显的问题会出现在我们的脑海中:当关系数据库运行良好,经过战斗测试,被业界接受,并且没有重大的持久性问题时,为什么需要NoSQL数据库呢
Scalability
基于SQL的关系数据库的一个很大的限制是可伸缩性。扩展关系数据库并不是一件小事。它们必须分片或复制,才能在集群中平稳运行。简而言之,这需要仔细的思考和人为的干预.
相反,NoSQL数据库能够动态地添加新的服务器节点并继续工作,无需任何人工干预,只需轻轻一敲手指.
如今的网站需要快速的读写能力。社交网络上有数百万,甚至数十亿的用户相互联系
每微秒都会产生大量数据,我们需要一个基础设施来管理这种指数级增长。
Clustering
NoSQL数据库被设计成在集群上智能运行。我说的智能,是指在人类干预最小的情况下。
今天,服务器节点甚至具有自我修复能力。很流畅。基础设施足够智能,可以从故障中自我恢复。
尽管所有这些创新并不意味着老式的关系数据库不够好&我们不再需要它们了
关系数据库仍然很有用,而且仍然很受欢迎。它们有一个特定的用例。我们已经在“何时选择关系数据库”一节中讨论了这个问题。
此外,NoSQL数据库不得不牺牲强大的一致性、ACID事务和更多的东西来横向扩展集群和跨数据中心
使用NoSQL数据库的数据更趋向于最终一致性,而不是强一致性.
因此,这显然意味着NoSQL数据库不是解决问题的灵丹妙药。这是完全好的,我们不需要银弹。我们不是在猎杀狼人,我们是在完成一项更艰巨的任务,将世界连接到网上.
在接下来的课程中,我将详细讨论NoSQL数据库的底层设计,以及为什么它们必须牺牲强一致性和事务。
NoSQL数据库的特点
在介绍中,我们了解到NoSQL数据库是构建在分布式环境中的集群上运行的,支持Web 2.0网站。现在,让我们来看看NoSQL数据库的一些特性。
NoSQL数据库的优点
首先,学习曲线比关系数据库要短。在使用关系数据库时,我们会花大量的时间学习如何设计良好的标准化表、建立关系、尽量减少连接等
Schemaless
在设计关系数据库的模式时,需要非常关注,以避免在将来遇到任何问题
可以将关系数据库看作一个严格的校长。所有的东西都要放在合适的地方,要整洁,东西要一致。但是NoSQL数据库有点放松。
没有严格强制的模式,可以随意处理数据。你总是可以改变东西,传播东西。实体没有关系。因此,事情是灵活的&你可以按照自己的方式去做。
不一定! !这种灵活性有利有弊。它非常灵活,对开发人员友好,没有连接和关系等,这使得它很好。
NoSQL数据库的缺点
inconsistency 不一致性
但它同时也带来了实体不一致的风险。由于实体分布在整个数据库中,因此必须在所有地方更新实体的新值。
如果不这样做,则会导致实体不一致。这对于关系数据库来说不是问题,因为它们保持数据的规范化。一个实体只驻留在一个地方。
不支持ACID事务
此外,NoSQL分布式数据库不提供ACID事务。虽然有一些人主张这样做,但并没有得到全球的支持。它们只是被限制在一个特定的实体层次结构或一个小区域,在那里它们可以锁定节点来更新它们。
结论
我第一次使用NoSQL数据存储是使用谷歌云数据存储。
我觉得一个好处是,我们不必是数据库设计方面的专家才能编写应用程序。事情相对简单,因为没有管理连接、关系、n+1查询问题等的压力。
只需用它的Key获取数据。你也可以称它为实体的id。这是一个常量O(1)操作,这使得NoSQL数据库非常快。
在过去,我设计了很多具有复杂关系的MySQL数据库模式。我认为使用NoSQL数据库要比使用关系数据库容易得多
如果我们需要对后端进行一些额外的调用,以在单独的调用中获取数据,这没什么区别。我们总是可以缓存频繁访问的数据来克服这个问题
Popular NoSQL Databases
业界常用的NoSQL数据库有MongoDB、Redis、Neo4J、Cassandra。
何时选择NoSQL数据库
Handling A Large Number Of Read Write Operations处理大量读写操作
当需要快速扩展时,可以使用NoSQL数据库。什么时候需要快速扩张.
当你的网站上有大量的读写操作时,NoSQL数据库最适合这些场景。由于它们能够动态地添加节点,因此它们能够以最小的延迟处理更多并发流量和大量数据
Flexibility With Data Modeling数据建模的灵活性
第二个提示是,在开发的初始阶段,当您不确定数据模型和数据库设计时,预计事情会快速变化。NoSQL数据库为我们提供了更多的灵活性。
Eventual Consistency Over Strong Consistency最终一致性优于强一致性
当我们可以放弃强一致性的时候,当我们不需要事务的时候,最好选择NoSQL数据库
一个很好的例子是一个社交网络网站,如Twitter,当一个名人的推特被爆红,全世界的人都在点赞和转发。在一段时间内,点赞数的上升或下降有关系吗
如果系统显示的点赞数不是500万个,而是500万零250个,这位名人肯定不会在意
当一个大型应用程序部署在遍布全球的数百个服务器上时,地理上分布的节点需要一些时间才能达成全球共识
在他们达成共识之前,实体的价值是不一致的。在一段时间后,实体的值最终变得一致。这就是最终一致性。
尽管这种不一致并不意味着存在任何类型的数据丢失。这只是意味着,数据需要很短的时间通过海底的互联网电缆在全球范围内传播,以达成全球共识,并变得一致.
我们一直都在经历这种行为。尤其是在YouTube上。通常你会看到一个视频有10个点击量和15个赞。这怎么可能。实际的浏览量已经超过了赞数。它只是视图的计数不一致,需要很短的时间来更新。我将在后面的课程中更详细地讨论最终一致性
Running Data Analytics运行数据分析
NoSQL数据库也最适合数据分析用例,在这些用例中,我们必须处理大量涌入的数据。
有专门用于用例的数据库,如时间序列数据库、宽列数据库、面向文档的数据库等。我将在后面的课程中详细讨论它们。
NoSQL比SQL更高效吗?
从技术基准的角度来看,关系数据库和非关系数据库的性能是一样的
不仅仅是技术,而是我们如何使用技术来设计我们的系统,从而影响性能.所以,不要被所有的炒作弄糊涂了。理解您的用例,然后相应地选择技术
性能,这完全取决于应用程序和数据库设计。如果我们使用更多的SQL连接。回应不可避免地需要更多的时间
如果我们去掉所有的关系和连接,SQL就变得和NoSQL一样了。
为什么流行的技术栈总是选择NoSQL数据库?
但为什么流行的技术堆栈总是选择NoSQL数据库?例如(MongoDB,ExpressJS,Angularjs / Reactjs,Nodejs)堆栈
大多数在线应用程序都有通用的用例。这些技术栈已经把它们覆盖了。这背后也有商业原因。
现在,网上有大量的教程&大量推广流行的技术堆栈。有了这些资源,初学者可以很容易地掌握它们并编写他们的应用程序,而不是独自研究其他技术
不过,我们并不总是需要坚持使用流行的堆栈。我们应该选择最适合我们用例的东西。没有基本规则,选择适合你的。
Polyglot Persistence(Polyglot持久性)
Polyglot持久性意味着使用几种不同的持久性技术来满足应用程序中不同的持久性需求。
假设我们正在编写一个像Facebook一样的社交网络
Relational Database
为了存储关系,比如用户的朋友,朋友的朋友,他们喜欢什么摇滚乐队,他们有什么共同的食物偏好等,我们会选择一个关系数据库,如MySQL。
Key Value Store
对于所有频繁访问的数据的低延迟访问,我们将使用像Redis或Memcache这样的键值存储来实现缓存。我们可以使用相同的Key-value数据存储来存储用户会话。现在我们的应用已经大获成功,非常受欢迎,我们有数百万活跃用户。
Wide Column Database宽列数据库
为了理解用户行为,我们需要建立一个分析系统来对用户生成的数据进行分析。我们可以使用像Cassandra或HBase这样的宽列数据库来实现这一点
ACID Transactions & Strong ConsistencyACID事务&强一致性
我们的应用程序的受欢迎程度似乎没有停止,它正在飙升。现在,企业希望在我们的门户网站上投放广告。为此,我们需要建立一个支付系统。同样,我们将选择一个关系数据库来实现ACID事务并确保强一致性。
Graph Database
现在,为了增强我们的应用的用户体验,我们必须开始向用户推荐内容,以保持他们的粘性。图形数据库最适合实现推荐系统。好了,到现在为止,我们的应用程序有多个功能,每个人都喜欢它。如果用户可以在我们的门户网站上搜索其他用户、业务页面和其他内容,并与他们建立联系,那该有多酷
Document Oriented Store面向文档的存储
为了实现这一点,我们可以使用一个开源的面向文档的数据存储,比如ElasticSearch。该产品在行业中很受欢迎,因为它在网站上实现了可伸缩的搜索功能。我们可以将所有与搜索相关的数据持久化到弹性存储中。
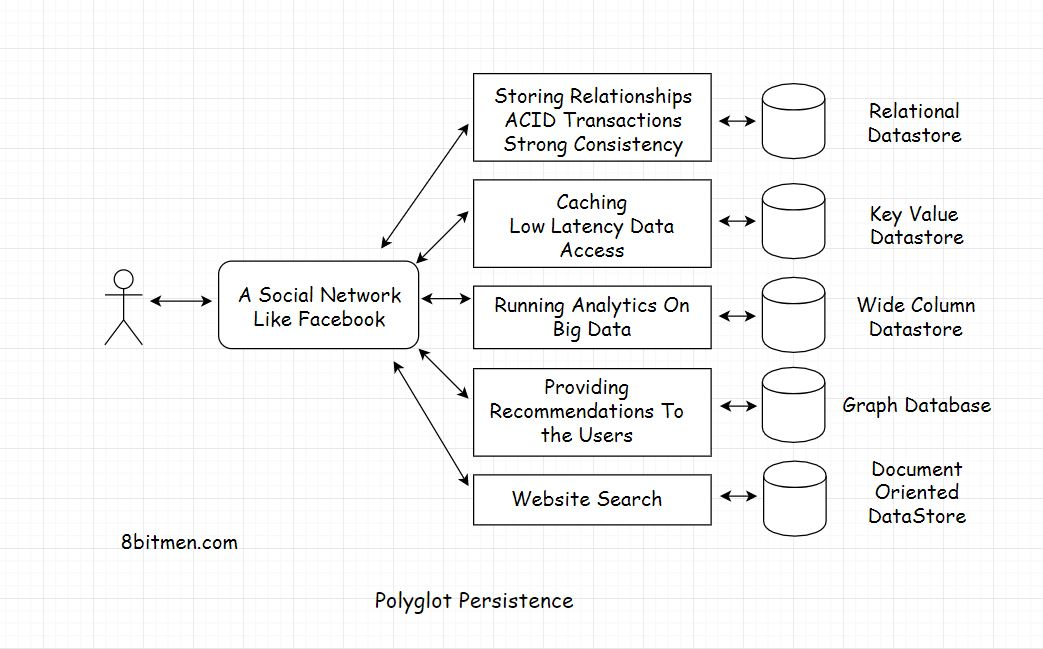
因此,这就是我们如何使用多个数据库来满足不同的持久性需求。不过,这种方法的一个缺点是使所有这些不同的技术协同工作的复杂性增加了。构建、管理和监控多种语言的持久性系统需要付出大量的努力。如果有更简单的东西呢?这样我们就不用自己动手收拾东西了
Multi-Model Databases
到目前为止,数据库只支持一种数据模型,它可以是关系数据库、图形数据库或具有特定数据模型的任何其他数据库
但是随着多模型数据库的出现,我们能够在单个数据库系统中使用不同的数据模型
多模型数据库支持多种数据模型,如图、面向文档、关系等,而不是只支持一种数据模型
它们还避免了在一个服务中管理多个持久性技术的需要。它们逐级降低了操作复杂性。对于多模型数据库,我们可以通过一个单一的API利用不同的数据模型
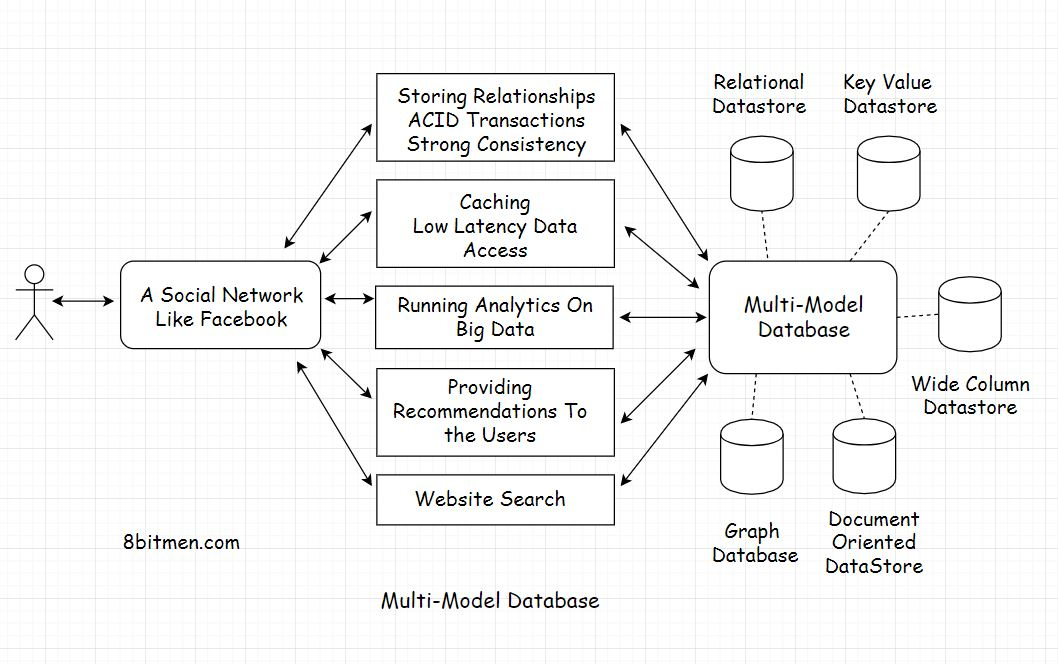
Popular Multi-Model Databases
目前流行的多模型数据库有Arango DB、Cosmos DB、Orient DB、Couchbase等。
到目前为止,我们已经清楚NoSQL数据库是什么以及什么时候选择它们。现在让我们来理解一些概念,比如最终一致性、强一致性,它们是理解分布式系统的关键
Eventual Consistency(最终一致性)
最终一致性是一种一致性模型,它使数据存储具有高可用性。它也被称为乐观复制&是分布式系统的关键。那么,它究竟是如何工作的呢?我们将通过用例来理解这一点。
想想一个流行的微博客网站,它分布在世界各地,比如亚洲、美洲和欧洲。此外,每个地理区域都有多个数据中心区:北、东、西、南。此外,每个分区都有多个集群,集群中运行多个服务器节点
因此,我们有许多分布在世界各地的数据存储节点,微博站点使用这些节点来持久化数据。
因为有这么多的节点在运行,所以不存在单点故障。数据存储服务高可用。即使有几个节点宕机,持久化服务作为一个整体仍然是正常的
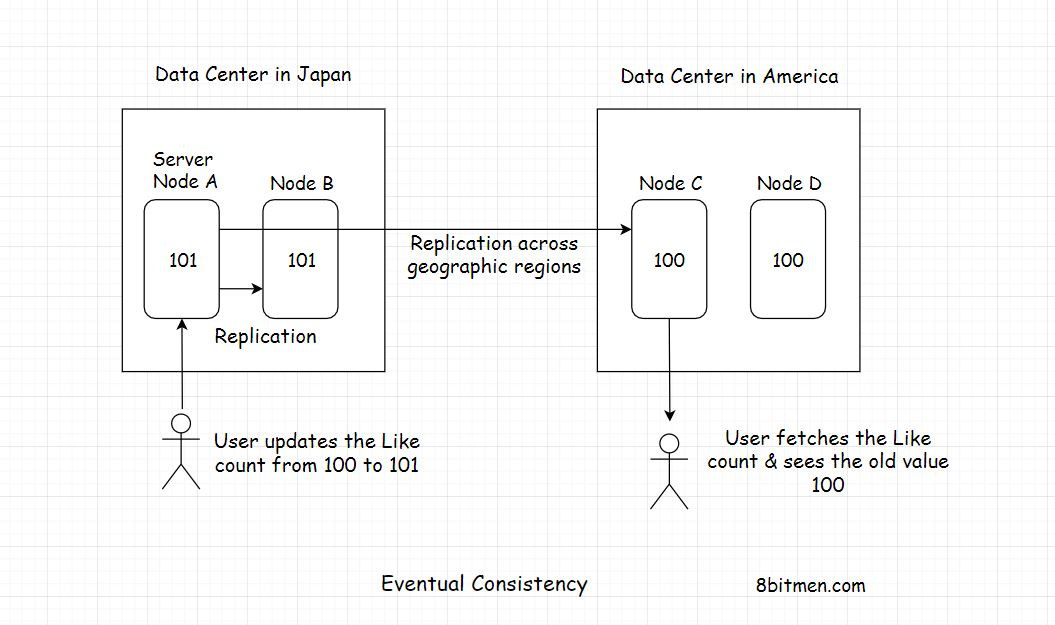
好吧,现在让我们假设一个名人在网站上发布了一个帖子,全世界的人都开始喜欢它。
在某一时刻,日本的一名用户对该帖子的点赞次数从100次增加到101次。在同一时间,在不同地理区域的美国用户点击了这篇文章,他看到的赞数是100,而不是101
这很简单,因为Post Like计数器的新更新值需要一些时间才能从日本转移到美国,并更新在那里运行的服务器节点。
尽管计数器在那个时间点的值是101,但美国用户看到的是旧的不一致的值。
但当他在几秒钟后刷新他的网页时,Like计数器的值显示为101。因此,数据最初是不一致的,但最终在部署在世界各地的服务器节点上得到一致。这就是最终一致性
让我们更进一步,如果在同一时间点,日本和美国的用户都喜欢这个帖子,而另一个地理区域的用户说欧洲的用户访问这个帖子。
不同地理区域内的节点都有不同的post值。他们需要一些时间才能达成共识
最终一致性的好处是,系统可以动态地添加新节点,而不需要阻塞其中任何一个节点,这些节点对最终用户来说都是可用的,可以随时进行更新
世界各地的数百万用户可以同时更新这些值,而不必等待系统在所有节点上达成一个共同的最终值,然后才进行更新。这个特性使系统具有高可用性。
最终一致性适用于值的准确性不太重要的用例,如上面讨论的用例。
最终一致性的其他用例可能是在保持在线观看Live视频流的用户数量时。当处理大量的分析数据时,数据上下偏差不要紧
但在某些情况下,数据必须精准如银行和股票市场。我们只是不能让我们的系统最终是一致的,我们需要强一致性。
Strong Consistency(强一致性)
强一致性仅仅意味着数据在任何时候都必须是强一致性的。世界上所有的服务器节点在任何时候都应该包含相同的实体值。实现这种行为的唯一方法是在更新时锁定节点
让我们继续上一课中关于最终一致性的例子。为了保证系统的强一致性,当日本用户喜欢该帖子时,必须锁定不同地理区域的所有节点,以防止并发更新。这意味着在某一时刻,只有一个用户可以更新发布的Like计数器值。
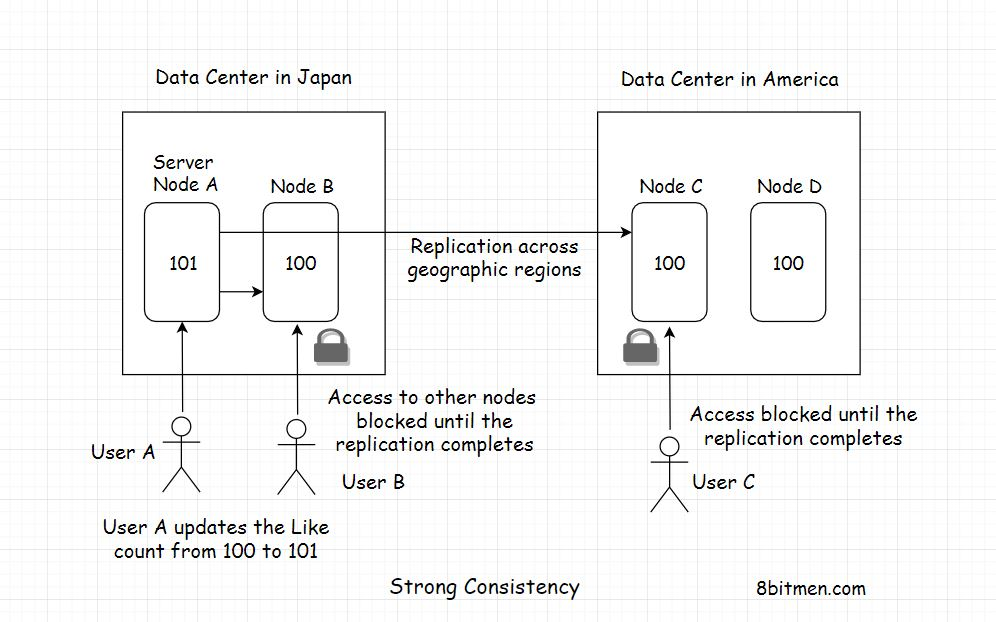
所以,一旦日本的用户将Like计数器从100更新到101。值将在所有节点上全局复制。一旦所有节点达成一致,锁就被解除
现在,其他用户可以喜欢这篇文章。如果节点需要一段时间才能达成共识,它们就必须等待到那时
当然,这在社交应用中是不理想的。但是,请考虑一个股票市场应用程序,其中用户在某个时间点看到同一只股票的不同价格,并同时更新它。这会造成混乱
因此,为了避免这种混乱,我们需要我们的系统是强一致性的。更新时必须锁定节点
将所有请求排队是使系统具有强一致性的一个好方法。这个实现超出了本课程的范围。尽管我们将讨论一个叫做CAP的定理,它是实现这些一致性模型的关键。
因此,到目前为止,我确信您已经意识到,选择强一致性模型会影响系统的高可用性。
当系统被一个用户更新时,不允许其他用户同时执行更新。这是实现一致的ACID事务的强度。
ACID Transaction Support
像NoSQL数据库这样的分布式系统可以横向扩展,但却不支持全局的ACID事务&这是由于它们的设计。NoSQL技术发展的全部原因就是它的高可用性和可扩展性。如果我们每次都要锁定节点,就会变得像SQL一样。
因此,NoSQL数据库不支持ACID事务,而那些声称支持ACID事务的数据库有适用于它们的条款和条件。
通常,事务支持仅限于地理区域或实体层次结构。该技术的开发人员确保所有强一致性实体节点都位于相同的地理区域,从而使ACID事务成为可能
CAP Theorem
CAP代表(Consistency, Availability, Partition Tolerance)一致性、可用性、分区容错性。我们已经详细讨论了一致性和可用性。分区容错意味着容错。系统可以容忍故障或分区。即使有几个节点坏了,它也能继续工作.
这个定理有很多定义,你可以在网上找到,在一致性、可用性和分区容忍度这三个概念中,我们必须选择两个。我觉得这有点让人困惑。我将试着给这个定理一个更简单的解释
CAP定理简单地指出,在网络故障的情况下,当系统的几个节点宕机时,我们必须在可用性和一致性之间做出选择
如果我们选择Availability可用性,这意味着当一些节点故障时,其他节点对用户可用以进行更新。在这种情况下,系统是不一致的,因为宕机的节点没有更新新的数据。当它们重新联机时,如果用户从它们获取数据,它们将返回它们停止时的旧值
如果我们选择Consistency一致性,在这种情况下,我们必须锁定所有节点以进行进一步的写操作,直到故障的节点重新联机。这将确保系统的强一致性,因为所有节点将具有相同的实体值。
在可用性和一致性之间做出选择很大程度上取决于我们的用例和业务需求。我们已经详细讨论过了。此外,从两个系统中选择一个的局限性是由于分布式系统的设计。我们不能同时拥有可用性和一致性
分布在全球各地的节点需要一些时间才能达成共识。除非我们传输数据的速度比时间快或以时间的速度,否则不可能有零延迟
#### Document Oriented Database
面向文档的数据库是NoSQL数据库的主要类型。它们在独立的文档中以面向文档的模型存储数据。数据通常是半结构化以类似json的格式存储。
数据模型与我们的应用程序代码中的数据模型相似,因此开发人员更容易存储和查询数据
面向文档的存储适合敏捷软件开发方法,因为在使用它们时,更容易根据不断变化的需求进行更改
Popular Document Oriented Databases
行业中使用的一些流行的面向文档的存储有MongoDB、CouchDB、OrientDB、谷歌Cloud Datastore、Amazon Document DB
何时选择面向文档数据库
如果您使用的是半结构化数据,则需要一个灵活的模式,它会经常变化。当你开始编写应用程序时,你并不确定数据库模式。随着时间的推移,事情可能会发生变化。你需要一些灵活的东西,你可以随着时间的推移改变最少的麻烦。选择一个面向文档的数据存储
面向文档的数据库的典型用例如下:
- 实时信息源
- 实时体育应用程序
- 编写产品目录
- 库存管理
- 存储用户评论
- 基于web的多人游戏
作为NoSQL数据库家族中的一分子,这些数据库提供了水平可伸缩性,高性能读写,因为它们迎合了CRUD——创建、读取、更新、删除用例。在没有太多关系逻辑的情况下,我们需要的只是数据的快速持久化和检索。
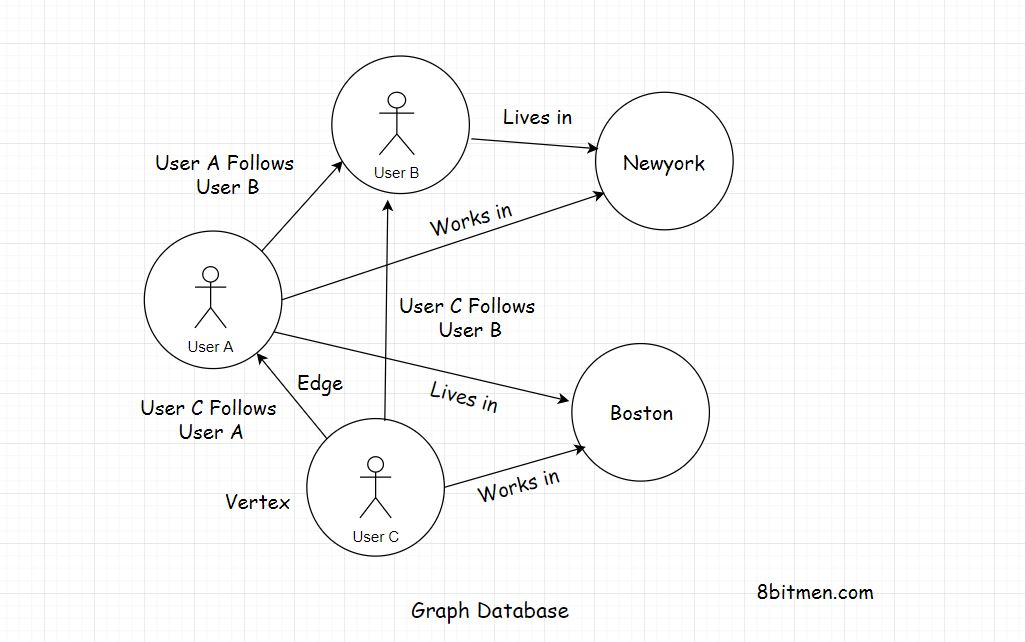
Graph Database
图形数据库也是NoSQL数据库系列的一部分。他们存储数据在节点/顶点和边缘以关系的形式。
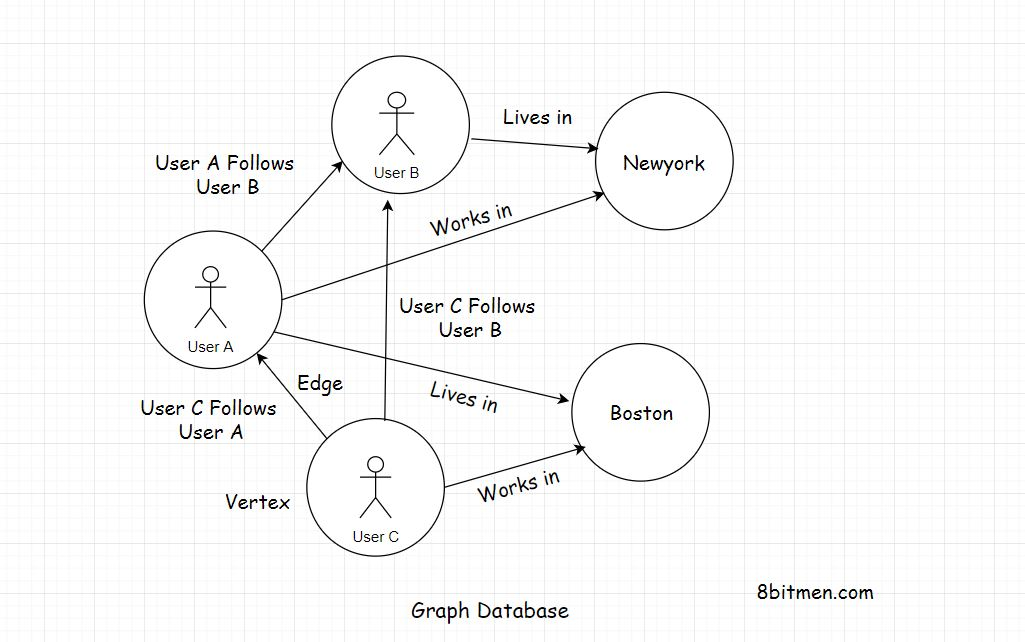
图形数据库中的每个节点代表一个实体。它可以是一个人,一个地方,一个企业等。边缘代表实体之间的关系。
既然已经有了基于SQL的关系数据库,为什么还要使用图形数据库来存储关系呢?
Features Of A Graph Database
- 首先是形象化。想象一下惊悚侦探电影中的钉板,钉在木板上的几个图像通过线连接起来。它确实有助于形象化实体是如何关联的,事物是如何组合在一起的。
- 第二个原因是低延迟。在图数据库中,关系的存储方式与关系数据库的存储方式略有不同。图数据库的速度更快,因为它们中的关系不是在查询时计算出来的,因为这是在关系数据库中的连接的帮助下发生的。这里的关系以边的形式保存在数据存储中,我们只需要获取它们。在查询时不需要运行任何类型的计算。
适合图形数据库的应用程序的一个很好的现实示例是谷歌Maps。节点表示城市,边表示城市之间的连接.现在,如果我必须寻找不同城市之间的道路,那么在运行查询时,我不需要通过连接来确定城市之间的关系。我只需要取回已经存储在数据库中的边
图数据库的理想用例是构建社会、知识、网络图。编写基于ai的应用、推荐引擎、欺诈分析应用、存储基因数据等。
#### Key Value Database
键值数据库也是NoSQL家族的一部分。这些数据库使用简单的键值方法来存储和快速获取数据,延迟最小
##### Features Of A Key Value Database
Key-value数据库的一个主要用例是在应用程序中实现缓存,因为它们确保了最小的延迟。
Key作为一个唯一的标识符,并且有一个与之相关联的值。该值可以像文本块一样简单,也可以像对象图一样复杂。
Key-value数据库中的数据可以在常量时间O(1)中获取,不需要查询语言来获取数据。这只是一个简单的不需要动脑筋的获取操作。这确保了最小的延迟
流行的KV存储
业界常用的键值数据存储有Redis、Hazelcast、Riak、Voldemort和Memcache。
何时选取
如果你有一个用例,你需要以最小的麻烦和后端处理快速获取数据,那么你应该选择一个键值数据存储。键值存储在超级快速获取数据的场景中非常有效
键值存储在超级快速获取数据的场景中非常有效。键值数据库的典型用例如下:
- 缓存
- 持久的用户状态
- 持久的用户会话
- 管理实时数据
- 实施队列
- 在线游戏和Web应用程序中创建排行榜
- 实施PUB子系统
Time Series Database
时间序列数据库为跟踪和持久的时间序列数据进行了优化
时间序列数据
它是包含与事件发生时间相关的数据点的数据。对这些数据点进行跟踪、监视,然后根据特定的业务逻辑最终进行聚合。时间序列数据通常来自物联网设备、自动驾驶汽车、行业传感器、社交网络、股市金融数据等。好吧! !但是,为什么需要存储如此大量的时间序列数据呢
##### 为何存储时间序列数据
研究来自应用程序的数据流有助于我们跟踪系统的行为。它帮助我们研究用户模式、异常现象以及事物如何改变时间。
时间序列数据主要用于运行分析,根据分析结果推断结论和制定未来的业务决策。运行分析还可以帮助产品不断发展
一般数据库不是用来处理时间序列数据的。随着物联网的出现,这些数据库变得非常流行,并被行业巨头采用。
常用的时间序列数据库
业界常用的时间序列数据库有DB、Timescale DB、Prometheus等
何时选用
如果你有一个用例,你需要在很长一段时间内实时地管理数据,那么时间序列数据库就是你所需要的
正如我们所知,时间序列数据库是用来处理实时流数据的。它的典型用例是从物联网设备获取数据。管理用于运行分析和监控的数据。编写一个实时处理股票价格变化的自主交易平台等
Wide-Column Database
宽列数据库属于NoSQL数据库家族,主要用于处理海量数据,技术上称为大数据 宽列数据库非常适合分析用例 它们具有高性能和可伸缩的架构 另外,宽列数据库也称为面向列的数据库,它将数据存储在具有动态列数的记录中 一条记录可以包含数十亿列
常用的宽列数据库
目前流行的宽列数据库有Cassandra、HBase、谷歌BigTable、Scylla DB等。
何时选用
如果你有一个用例需要处理大数据,吸收数据或对其进行分析,那么宽列数据库非常适合这个场景
宽列数据库用于管理大数据,同时确保可伸缩性、性能和高可用性
Caching
缓存是任何应用程序性能的关键。它确保了低延迟和高吞吐量。具有缓存的应用程序肯定会比没有缓存的应用程序做得更好,这是因为与没有实现缓存的应用程序相比,它返回响应的时间更短。
在web应用程序中实现缓存仅仅意味着从基于磁盘硬件的数据库中复制频繁访问的数据,并将其存储在RAM随机访问内存硬件中。
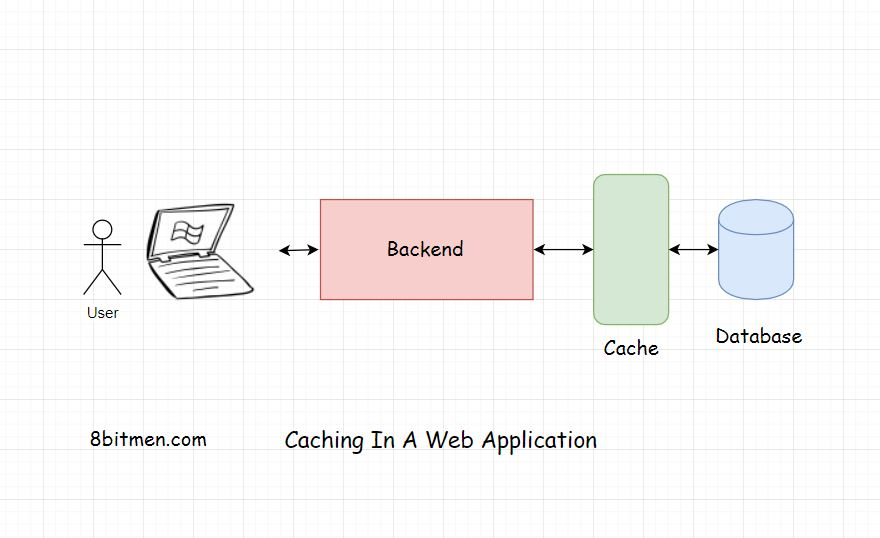
基于ram的硬件比基于磁盘的硬件提供更快的访问。正如我前面所说的,它确保了低延迟和高吞吐量。吞吐量指的是网络调用的数量,即客户端和服务器之间在规定的时间内的请求-响应
#### 缓存动态数据
使用缓存,我们可以缓存静态数据和动态数据。动态数据是变化更频繁的数据,它有一个过期时间或TTL生存时间。TTL结束后,数据从缓存中清除,新更新的数据保存在缓存中。这个过程被称为缓存失效。
缓存静态数据
静态数据包括图像,字体文件,CSS和其他类似的文件。这是一种不经常更改的数据,可以很容易地在客户端浏览器或本地内存中缓存。此外,在cdn上,内容分发网络
缓存还有助于应用程序在网络中断期间保持预期的行为
我如何确定我的应用程序中是否需要缓存
首先,使用缓存总是一个好主意,而不是不使用它。这没有什么坏处。它可以在应用程序的任何层使用&对于它可以和不能应用在哪里没有基本规则。
缓存最常见的用法是数据库缓存。通过截取路由到数据库的数据请求,缓存有助于减轻对数据库的压力。
然后,缓存返回所有经常访问的数据。因此,逐级降低数据库上的负载。
应用程序体系结构中可以使用缓存的不同组件
在我们的应用程序的架构中,我们可以在多个地方使用缓存。在客户端浏览器中使用缓存来缓存静态数据。它与数据库一起用于拦截所有的数据请求,在REST API实现中等等。
除了这些地方,我建议你去寻找规律。我们总是可以缓存经常访问的内容在我们的网站上,从任何组件。当它可以被缓存时,不需要反复计算。
想想关系数据库中的join。它们因反应缓慢而臭名昭著。更多的join意味着更多的延迟。通过存储需要的数据,缓存可以避免每次运行连接的需要。现在,想象一下这个机制会对我们的应用程序提速多少.
而且,即使数据库坏了一段时间。用户不会注意到它,因为缓存将继续服务于数据请求。
我们可以在缓存中存储用户会话。它可以在应用程序的任何层实现,可以在操作系统级、网络级、CDN或数据库
你可能还记得,我们在数据库课上讨论过键值数据存储。它们主要用于在web应用程序中实现缓存
它们可以用于微服务体系结构中的跨模块通信,保存所有服务共同访问的共享数据。它充当微服务通信的骨干。
通过缓存的键值数据存储也广泛用于内存数据流处理和运行分析。
通过缓存降低应用程序部署成本
例如开发并部署在云上的一个以股票为基础的游戏应用程序
游戏中有几只公司的股票在股票市场上上市,算法会每秒钟触发这些股票的价格运动,如果不是在这之前。
最初,只要价格发生变化,我就将更新后的股票价格保存在数据库中,以便在一天结束时创建一个股价运动时间表。但是这么多的数据库写入花费了我一大笔钱。每小时的写作数量简直是疯了。
最终,我决定不在数据库中保存每秒钟更新的价格,而是使用Memcache来保存股票价格。然后定期运行批处理操作来更新数据库。
Memcache比基于磁盘的数据库访问要便宜得多。缓存处理所有的股票价格请求,直到批处理操作运行,数据库才有更新的值
对于现实生活中的金融科技应用来说,这个调整可能并不理想,但它帮助我节省了一大笔钱&我能够运行游戏更长的时间
所以,伙计们! !这是一个可以利用缓存机制来降低成本的实例。您可能不希望将每个信息都持久化到数据库中,而希望使用缓存来存储不太关键的信息。
现在让我们来看看一些缓存策略,我们可以利用这些策略来进一步提高应用程序的性能。
#### Caching Strategies
服务于特定用例的缓存策略有不同的种类。它们是缓存搁置,透读缓存,透写缓存和回写缓存
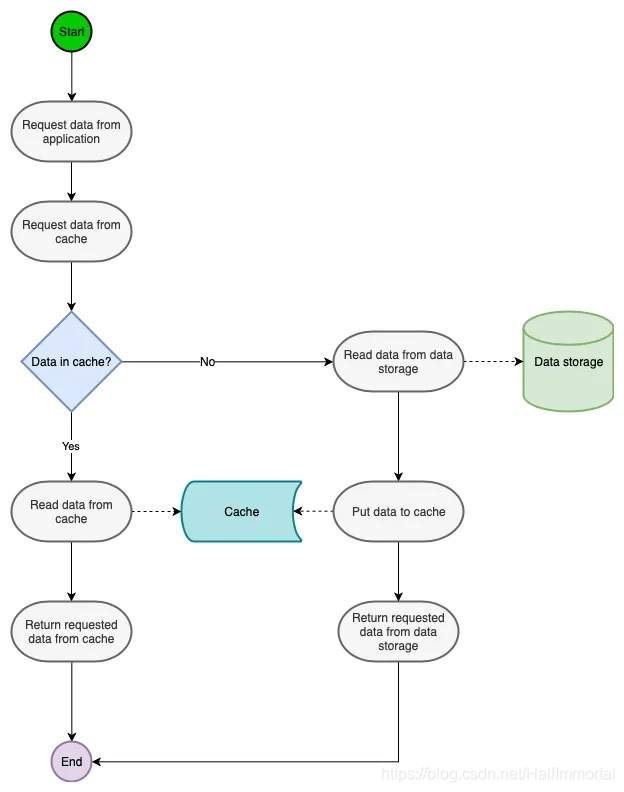
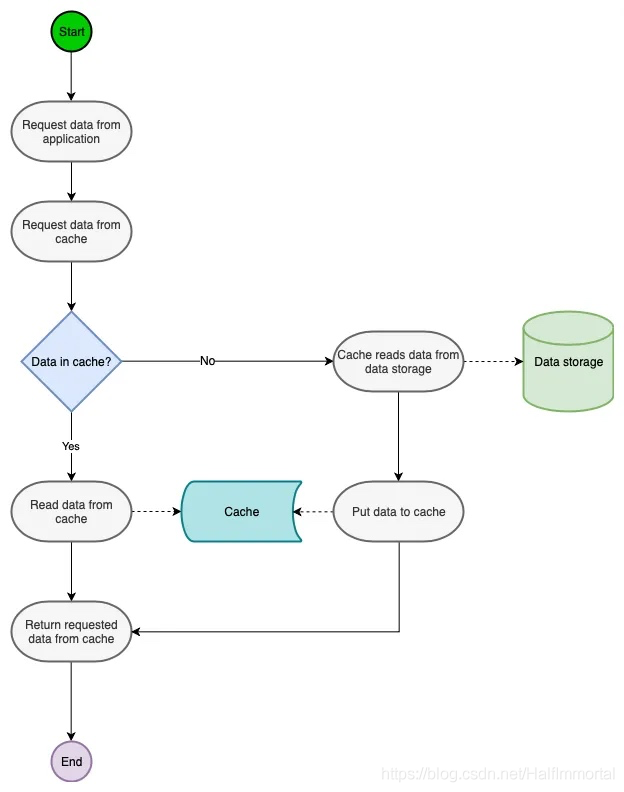
Cache Aside
这是最常见的缓存策略。在这种方法中,缓存与数据库一起工作,试图尽可能地减少对它的命中
数据是在缓存中惰性加载的。当用户发送对特定数据的请求时,系统首先在缓存中查找它。如果存在,则直接从它返回。如果不是,则从数据库中获取数据,更新缓存并返回给用户。
这种策略最适用于读量大的工作负载。这包括不经常更新的数据类型,例如门户中的用户概要数据。用户名、帐号等
该策略中的数据直接写入数据库。这意味着缓存中的数据和数据库中的数据可能不一致。为了尽量减少读写不一致的情况.缓存上的数据有一个TTL Time To Live。在规定的时间之后,缓存中的数据将失效。
Read-Through
这个策略与缓存搁置策略非常相似。与Cache Aside策略的一个微妙区别是,在Read-through策略中,缓存始终与数据库保持一致。
缓存库或框架承担了与后端保持一致性的责任;这种策略中的信息也是惰性加载的,只有当用户请求时才会加载到缓存中。当第一次请求信息时,它会导致缓存丢失。然后后端必须在向用户返回响应时更新缓存,开发人员总是可以将用户最希望请求的信息预加载到缓存中
Read-Through和Cache-Aside很相似,不同点在于程序不需要再去管理从哪去读数据(缓存还是数据库)。相反它会直接从缓存中读数据,该场景下是缓存去决定从哪查询数据。当我们比较两者的时候这是一个优势因为它会让程序代码变得更简洁。
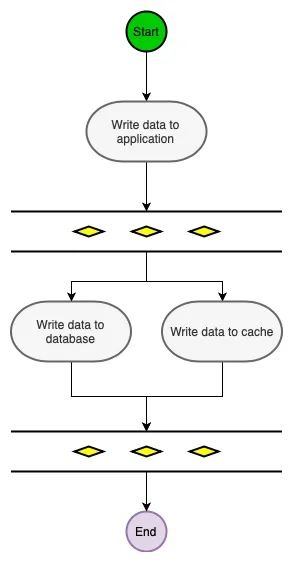
Write-Through
Write-Through下所有的写操作都经过缓存,每次我们向缓存中写数据的时候,缓存会把数据持久化到对应的数据库中去,且这两个操作都在一个事务中完成。因此,只有两次都写成功了才是最终写成功了。这的确带来了一些写延迟但是它保证了数据一致性。
同时,因为程序只和缓存交互,编码会变得更加简单和整洁,当你需要在多处复用相同逻辑的时候这点变的格外明显。
在这个策略中,写入数据库的每一个信息都要经过缓存。在数据写入数据库之前,缓存会用数据更新。这保持了缓存和数据库之间的高一致性,尽管它在写操作期间增加了一点延迟,因为数据要在缓存中另外更新。这适用于编写繁重的工作负载,如在线大型多人游戏。
此策略通常与其他缓存策略一起使用,以实现最佳性能。
当使用Write-Through的时候一般都配合使用Read-Through。
Write-Through适用情况有:
需要频繁读取相同数据 不能忍受数据丢失(相对Write-Behind而言)和数据不一致 Write-Through的潜在使用例子是银行系统。
Write-Back
Write-Back和Write-Through在“程序只和缓存交互且只能通过缓存写数据”这一点上很相似。不同点在于Write-Through会把数据立即写入数据库中,而Write-Back会在一段时间之后(或是被其他方式触发)把数据一起写入数据库,这个异步写操作是Write-Back的最大特点。
数据库写操作可以用不同的方式完成,其中一个方式就是收集所有的写操作并在某一时间点(比如数据库负载低的时候)批量写入。另一种方式就是合并几个写操作成为一个小批次操作,接着缓存收集写操作(比如5个)一起批量写入。
异步写操作极大的降低了请求延迟并减轻了数据库的负担。同时也放大了数据不一致的。比如有人此时直接从数据库中查询数据,但是更新的数据还未被写入数据库,此时查询到的数据就不是最新的数据。
这种策略有助于极大地优化成本。在Write-back缓存策略中,数据直接写入缓存,而不是写入数据库。缓存根据业务逻辑延迟一段时间后将数据写入数据库.
如果应用程序中有相当多的写操作。开发人员可以减少写数据库的频率,以减少负载和相关的成本。
这种方法的一个风险是,如果缓存在更新DB之前失败,数据可能会丢失。同样,这个策略与其他缓存策略一起使用,以充分利用这些策略
Message Queues
消息队列,顾名思义,是一个将消息从源路由到目的地的队列,也可以说是从发送方路由到接收方的队列。
由于它是一个队列,它遵循FIFO(先进先出)策略。先发送的消息先传递。虽然消息有一个优先级,使队列成为优先队列,但现在让我们保持简单。
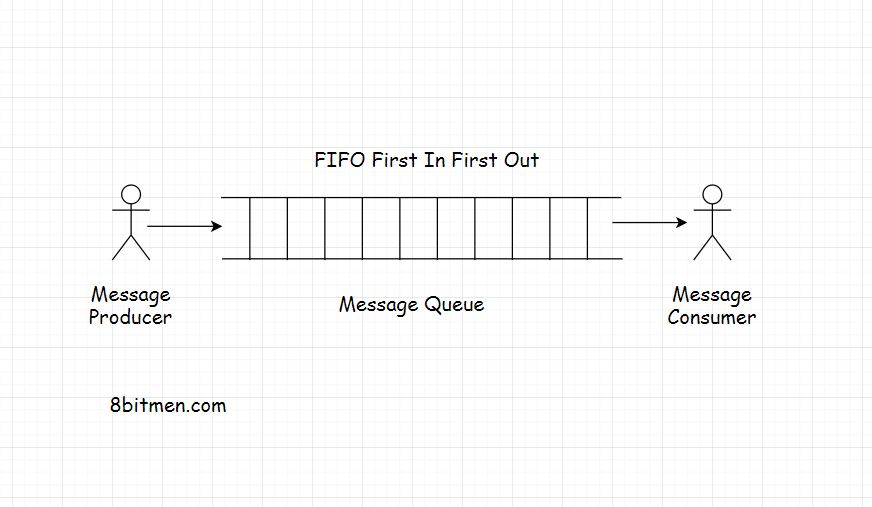
消息队列的特点
消息队列促进了异步行为。在AJAX课程中,我们已经了解了什么是异步行为。异步行为允许模块在后台相互通信,而不会妨碍它们的主要任务
消息队列促进了跨模块通信,这是面向服务或微服务体系结构中的关键。它允许在异构环境中进行通信。它们还为消息提供临时存储,直到消息被消费者处理和使用为止
以电子邮件为例,邮件的发送者和接收者不需要同时在线才能互相交流。发送方发送电子邮件,邮件暂时存储在邮件服务器上,直到收件人联机并读取邮件
消息队列使我们能够运行后台进程、任务、批处理作业。说到后台进程,让我们借助一个用例来理解这一点。
想象一个用户在门户网站上注册。在他注册后,他立即被允许导航到应用程序的主页,但注册过程还没有完成。系统必须向用户注册的电子邮件id发送确认邮件。然后用户需要点击确认邮件来确认注册事件。
但网站不能让用户等待,直到它发送电子邮件给用户。他要么被允许导航到主页,要么被弹开。因此,这个任务被分配给一个消息队列作为一个异步后台进程。当用户继续浏览网站时,它会向用户发送一封电子邮件进行确认。
这就是如何使用消息队列向web应用程序添加异步行为。消息队列也用于实现通知系统,就像Facebook通知一样。我将在接下来的课程中讨论这个问题。
运行批处理作业的消息队列
现在来看看批处理作业。您还记得在上一节缓存课中讨论的场景吗?在该场景中,我讨论了如何使用缓存来降低应用程序部署成本
在数据库中定期更新股票价格的批处理作业是由消息队列运行的。
所以,我们现在有了一个基本的了解,有一个消息发送者,也被称为生产者,还有一个消息接收者,也被称为消费者
生产者和消费者不需要驻留在同一台机器上进行通信,这是非常明显的
在通过队列路由消息的过程中,我们可以根据业务需求定义几个规则。我曾指出,为消息添加优先级。队列的其他重要特性包括消息确认、重试失败消息等
谈到队列的大小,没有明确的大小,它可以是一个无限的缓冲区,这取决于业务所拥有的基础设施
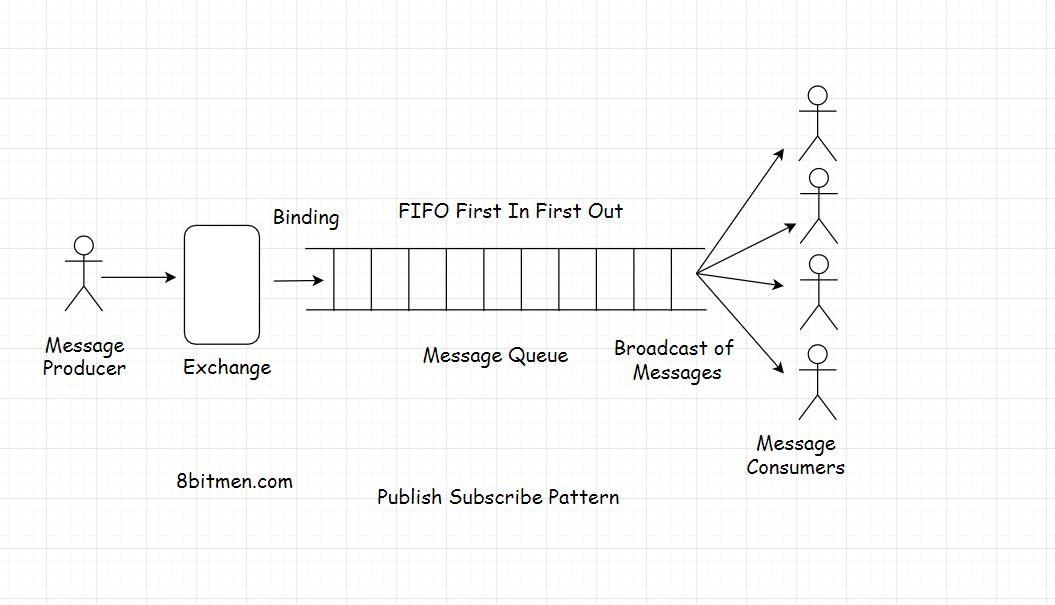
现在,我们将研究行业中广泛使用的消息传递模型,从发布订阅消息路由模型开始,该模型在当今的在线领域中非常流行。同时,这也是我们消费信息的方式。
Publish Subscribe Model 发布订阅模型
发布-订阅模型是指多个消费者从单个或多个生产者接收到相同消息的模型。
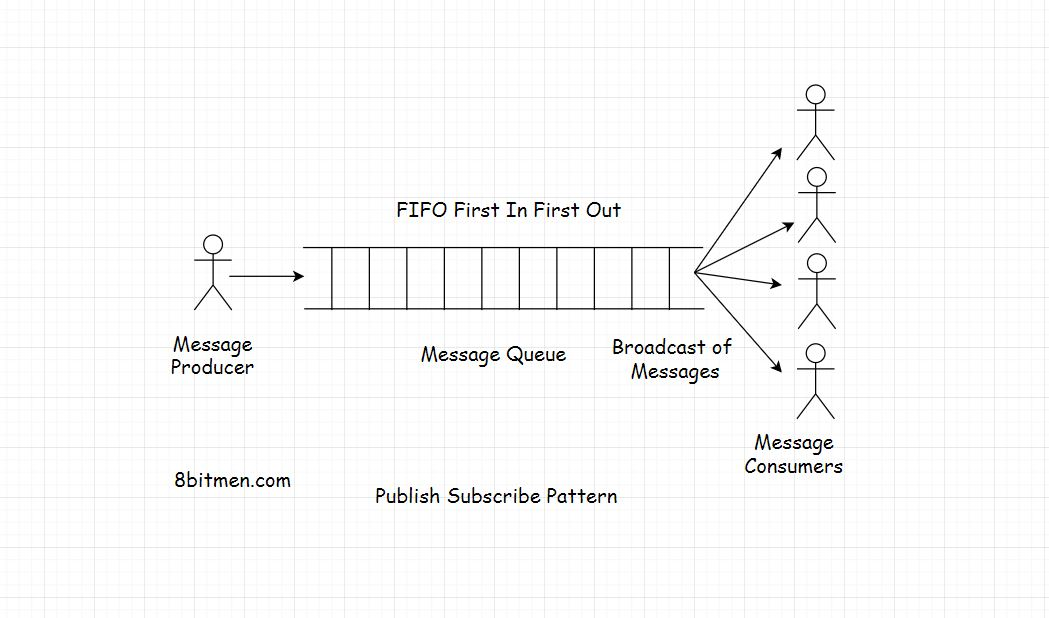
现实世界的报纸服务是发布-订阅模式的一个很好的类比,在这种模式中,消费者订阅报纸服务,服务每天将新闻传递给其服务的多个消费者
在网络世界中,我们经常订阅应用程序中的各种主题,以不断地获得任何特定部分的最新更新。无论是体育、政治还是经济等等
exchange(交换器)
要实现pub-sub模式,消息队列有exchanges,根据交换器类型和所设置的规则,交换器进一步将消息推送到队列中。交换器就像电话交换器一样,通过基于某种逻辑的基础设施将消息从发送者路由到接收者。
消息队列中有不同类型的exchange,其中一些是direct,topic,、headers,fanout.。为了更深入地了解这些不同的交换类型是如何工作的,RabbitMQ 的这篇文章很值得一读。
并不一定每个消息队列技术都具有相同的交换类型。这些只是我在这里讨论的一般情况。技术可以改变一切。此外,技术并不重要,你现在需要的只是对事物如何工作的一个概念
因此,我们将选择扇出交换类型来广播来自队列的消息。交换将消息推送到队列中,消费者将收到消息。交换和队列之间的关系称为绑定
point to point route 点对点的线路
点对点通信是一个非常简单的用例,来自生产者的消息只被一个消费者使用
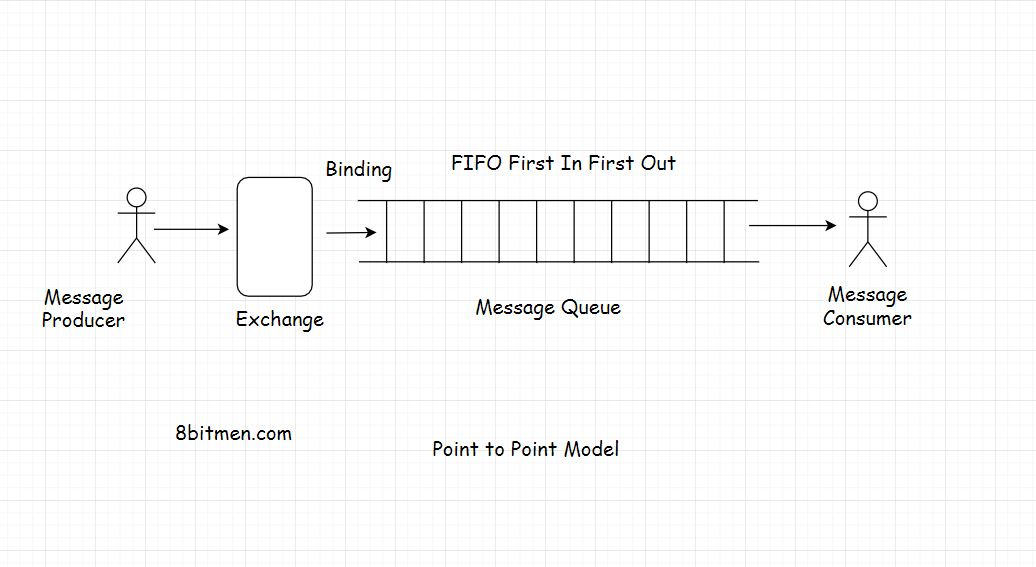
尽管基于业务需求,我们可以在这个消息传递模型中设置多个组合,比如在队列中添加多个生产者和消费者。但是在一天结束的时候,生产者发送的信息只会被一个消费者消费。因此被称为“点对点排队模型”。它不是消息的广播,而是实体对实体的通信。
Messaging Protocols
在处理消息队列时,有两个常用的协议。AMQP高级消息队列协议& STOMP简单或面向流文本的消息协议。
常用技术
谈到业界广泛使用的队列技术,有RabbitMQ、ActiveMQ、Apache Kafka等。
Notification Systems & Real-time Feeds with Message Queues (通知系统&实时消息队列)
我们将深入了解如何在消息队列的帮助下设计通知系统和实时提要。然而,这些模块在当今的Web 2.0应用程序中非常复杂。它们包括机器学习、理解用户行为、推荐新的相关信息以及与之整合的其他模块等。我们不会深入到那样的复杂程度,因为这不是必须的
假设我们正在使用关系数据库编写一个像Facebook这样的社交网络,我们将使用一个消息队列将异步行为添加到应用程序中。
在应用程序中,用户将拥有许多朋友和追随者。这是一个多对多的关系,就像一个社交图。一个用户有很多朋友,他会成为很多用户的朋友。就像我们在图形数据库课上讨论的那样
所以,当用户在网站上创建一个帖子时,我们会将它持久化到数据库中。将有一个User表和另一个Post表。因为一个用户会创建多个帖子,所以用户和他的帖子之间是一对多的关系。
同时,由于我们将帖子持久化到数据库中,我们必须将用户创建的帖子显示在他的朋友和关注者的主页上,甚至在需要的时候发送通知。
简单方法
在不使用消息队列的情况下实现此功能的一种简单方法是,对于网站上的每个用户,如果他的任何连接有新的更新,则定期短时间轮询数据库
为此,首先,我们将找到用户的所有连接,然后逐个检查每个连接,如果他们创建了一个新的帖子
如果有,查询将拉出由用户的连接创建的所有新文章,并显示在其主页上。我们也可以发送通知给用户,在用户表的通知计数器列的帮助下跟踪那些的计数&添加一个额外的AJAX轮询查询从客户端为新的通知
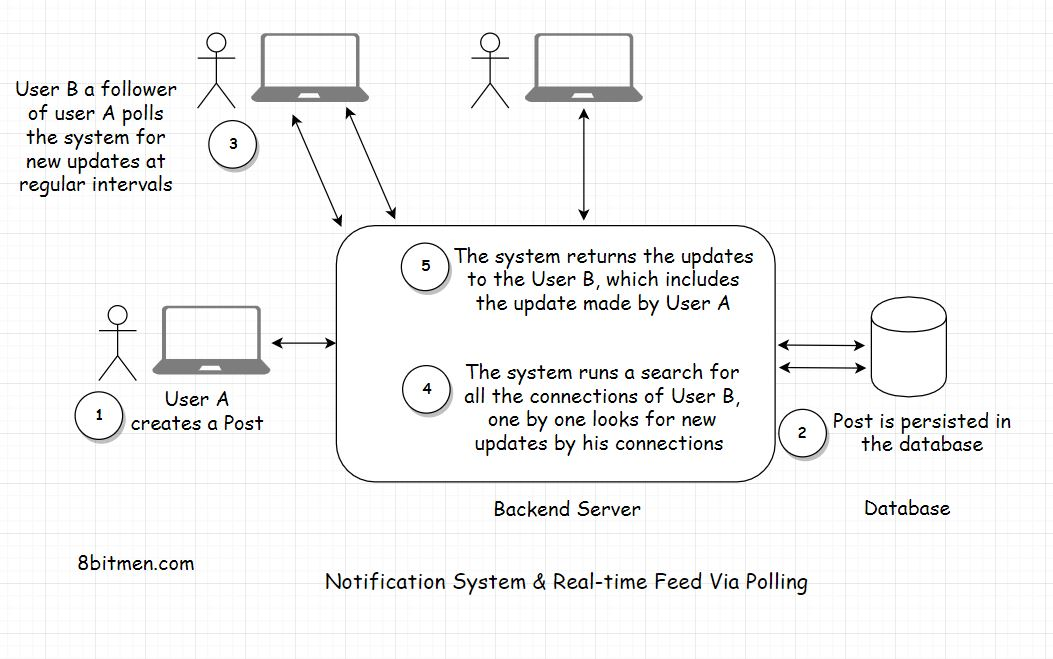
缺点
首先,我们经常轮询数据库,这是昂贵的。它将消耗大量的带宽,也将给数据库带来很多不必要的负载
第二个缺点是,在用户连接的主页上显示的用户帖子将不是实时的。在数据库被轮询之前,帖子不会显示。我们可以称之为实时,但并不是真正的实时
消息队列设计
这一次当用户创建一个新帖子时,它将拥有一个分布式事务。一个事务将更新数据库,另一个事务将发送负载到消息队列。有效负载指的是用户发布的消息的内容。
通知系统和实时提要(real-time feeds)与数据库建立持久连接,以促进数据的实时流。我们已经谈过了
消息队列在接收到消息时将立即异步地将消息推送到在线用户的连接中。它们不需要定期轮询数据库以检查用户是否创建了一个帖子。
我们也可以使用消息队列临时存储和一个TTL时间来等待用户的连接上线&然后将更新推送给他们。我们还可以使用单独的Key-value数据库来存储将通知推送到用户连接所需的用户详细信息。比如他关系网的id之类的。这将避免甚至轮询数据库以获取用户连接的需要
Handling Concurrent Requests With Message Queues(使用消息队列处理并发请求)
当全世界数以百万计的用户同时更新一个实体时,我们可以将所有更新请求排在一个高吞吐量消息队列中。然后我们可以用先进先出的方法一个接一个地处理它们
这将使系统高可用性,开放更新,同时仍然保持一致.
尽管这种方法的实现并不像听起来那么简单,但在分布式实时环境中实现任何东西都不是那么简单。
Facebook的LIVE视频流服务处理
Facebook的LIVE视频流服务处理并发用户请求的方法,也是利用队列来有效处理流量激增的一个很好的例子
在这个平台上,当一个受欢迎的人去LIVE时,LIVE流媒体服务器上的用户请求会激增。为了避免服务器上的传入负载,Facebook使用缓存来拦截流量.
但是,由于数据是实时流的,在请求到达之前,缓存通常没有填充实时数据。现在,这将很自然地导致缓存丢失&请求将继续访问流服务器
为了避免这种情况,Facebook将所有用户请求排成队列,请求相同的数据。它从流服务器获取数据,填充缓存,然后从缓存处理排队的请求
Rise Of Data-Driven Systems 数据驱动系统的崛起
我们今天的世界很大程度上是由数据驱动的,并正朝着完全由数据驱动的方向发展。随着物联网的出现,实体有了一定程度的自我意识,它们正在以前所未有的速度在线生成和传输数据。它们能够相互沟通,无需任何人为干预就能做出决定
物联网数据
物联网设备的主要大规模应用领域是工业传感器、智慧城市、电子设备、可穿戴医疗身体传感器等
为了管理大量的流式数据,我们需要有复杂的后端系统,从中收集有意义的信息,并归档/清除没有意义的数据
我们拥有的数据越多,我们的系统发展得就越好。今天的企业依赖于数据。他们需要客户数据来制定未来的计划和预测。他们需要了解用户的需求和他们的行为。所有这些都使企业能够创造更好的产品,做出更明智的决定,运行有效的广告活动,向他们的客户推荐新产品,获得更好的市场洞察等
所有这些对数据的研究最终会导致更多以客户为中心的产品和更高的客户忠诚度。
跟踪服务效率
处理流入数据的另一个用例是跟踪服务效率,例如,从数百万客户使用的物联网设备获得一切正常的信号
所有这些用例使得流处理成为业务和现代软件应用的关键。时间序列数据库是我们讨论过的一种技术,它可以对从物联网设备获取的实时数据进行持久化和查询
Data Ingestion(数据获取)
数据摄入是一个集合术语,指从几个不同的来源收集数据流,并使其准备由系统处理的过程。
在数据处理系统中,数据从物联网设备和其他来源摄取到要分析的系统中。它通过数据流水线路由到不同的组件/层,算法在其上运行,最终归档。
Layers Of Data Processing Setup(数据处理初始化层)
此整个数据处理初始化中有几个阶段/层,如:
- 数据收集层
- 数据查询层Data处理层
- 数据可视化层
- 数据存储层
- 数据安全层
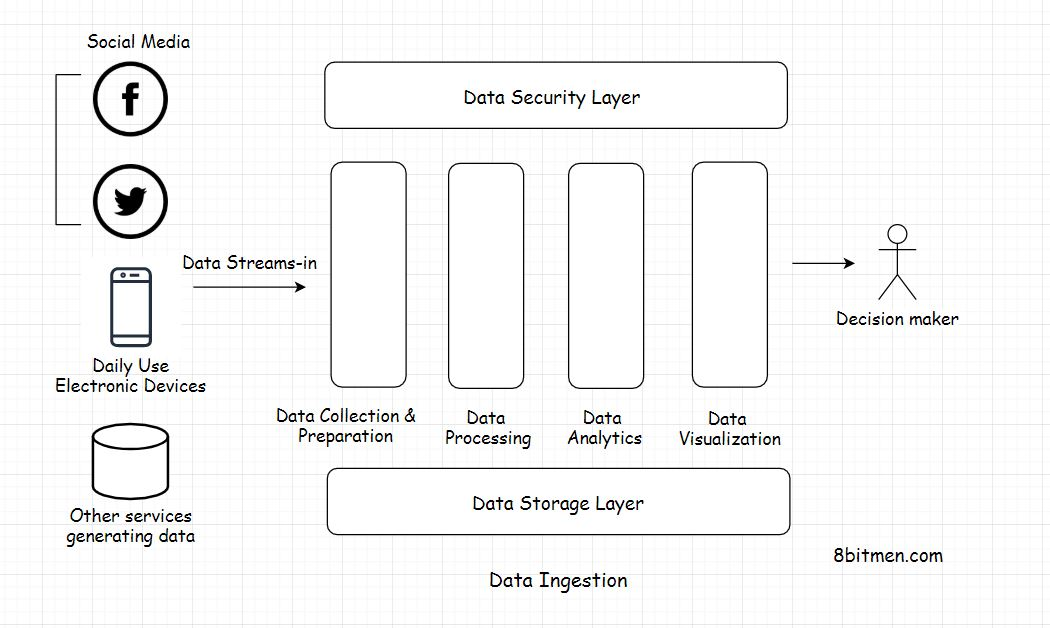
Data Standardization
从几个不同来源流进来的数据不是同构的结构格式。我们已经学习了不同类型的数据,结构化的,非结构化的,半结构化的。因此,您已经对什么是非结构化异构数据有了一个概念
来自网络服务、社交网络、物联网设备、工业机器等的数据以不同的速度和大小流入系统。每个数据流都有不同的语义
因此,为了使数据统一并适合处理,必须首先收集数据并将其转换为标准化格式,以避免将来出现任何处理问题。这个数据标准化的过程发生在数据收集和准备层
Data Processing
数据转换为标准格式后,将被路由到数据处理层,在那里根据业务需求对数据进行进一步处理。它通常分为不同的流,路由到不同的目的地。
Data Analysis
路由后,将对数据进行分析,包括执行不同的分析模型,如预测建模、统计分析、文本分析等。所有的分析事件都发生在数据分析层。
Data Visualization
一旦分析工作完成,我们就能从中获得有价值的情报。所有的信息都被路由到数据可视化层,然后呈现给涉众,通常是在一个基于web的仪表盘中。Kibana是数据可视化工具的一个很好的例子,在行业中非常流行
Data Storage & Security
移动数据极易受到安全漏洞的影响。数据安全层保证了数据的安全移动。说到数据存储层,顾名思义,它在持久化数据方面很有用
因此,这是如何为业务用例处理和分析大量数据的要点。这只是鸟瞰。数据分析领域非常深入,每一层的深入详细的微观视图需要专门的数据分析课程。
Different Ways Of Ingesting Data & the Challenges Involved(吸收数据的不同方式和所涉及的挑战)
Different Ways To Ingest Data(吸收数据的不同方式)
有两种主要的获取数据的方式,实时(real-time)和定期(intervals)运行的批量(batches)。从两者中选择哪一个完全取决于业务需求
在通过可穿戴物联网传感器读取心跳、血压等医疗数据的系统中,实时数据摄入通常是首选,因为时间至关重要。此外,在处理金融数据的系统中,如股票市场事件等。这是时间、生命和金钱紧密相连的几个例子,我们需要尽快获得信息。
相反,在读取趋势的系统中,我们总是可以批量获取数据。例如,当估计一个地区在一段时间内的体育受欢迎程度时
让我们谈谈开发人员在消化大量数据时必须面对的一些挑战。我添加这一课只是为了让你对整个过程有一个更深入的了解。在下一课中,我还将讨论应用程序开发领域中数据流的一般用例。
Challenges with Data Ingestion (数据吸收的挑战)
slow process
数据吸收是一个缓慢的过程。为什么?我之前提到过。当数据从几个不同的来源流入系统时,来自每个不同来源的数据都有不同的格式、不同的语法和附加的元数据。数据作为一个整体是异构的。它必须转换成一种常见的格式,如JSON或其他能够被分析系统很好地理解的格式
数据转换是一个冗长乏味的过程。这需要大量的计算资源和时间。流动的数据必须在管道中分几个阶段进行处理,然后向前移动
此外,在每一个阶段,数据都必须经过认证和验证,以满足组织的安全标准。在传统的数据清理过程中,获取手头有用的信息需要花费数周甚至数月的时间。传统的数据摄取系统,如ETL已经不再有效
why slow
现代数据处理技术和框架正在不断发展,以打破传统数据处理系统的局限性。在传统的系统中,实时数据摄取是不可能的
从实时处理中获得的分析信息并不是那么准确和全面,因为分析持续地运行在有限的数据集上,而不是考虑整个数据集的批处理方法。所以,基本上,我们花越多的时间研究数据,我们得到的结果就越准确
当我们学习数据处理的Lambda和Kappa架构时,您将了解更多这方面的知识
Complex & Expensive(复杂和昂贵的)
整个数据流过程是资源密集型的。在将数据输入系统之前,必须进行大量的工作来准备数据。而且,这不是一个次要的过程,需要一个专门的团队来完成这样的工作
工程团队经常遇到这样的情况:市场上可用的工具和框架不能满足他们的需求,他们别无选择,只能从基本框架编写一个定制的解决方案
Gobblin是LinkedIn的一个数据摄取工具。LinkedIn曾一度有15个数据吸收管道在运行,这给数据管理带来了一些挑战。为了解决这个问题,LinkedIn在内部编写了Gobblin。
来自外部源的数据的语义有时会发生变化,因为它们并不总是在我们的控制之下,这就需要在后端数据处理代码中进行更改。如今,行业中的物联网机器正在持续快速发展
这些是我们在设置数据处理和分析系统时必须牢记的因素
Moving Data Around Is Risky(移动数据是危险的)
当数据被四处移动时,就有可能出现漏洞。移动数据是脆弱的。它要经过几个不同的准备阶段&工程团队必须投入额外的努力和资源,以确保他们的系统在任何时候都符合安全标准
Data Ingestion Use Cases(数据摄取用例)
Moving Big Data Into Hadoop(将大数据转移到Hadoop)
这是最流行的数据摄取用例。如前所述,来自物联网设备、社交应用和其他来源的大数据流通过数据管道,转移到最流行的分布式数据处理框架Hadoop进行分析和处理。
Streaming Data from Databases to Elasticsearch Server(将数据从数据库流传输到Elasticsearch Server)
Elasticsearch是一个开源框架,用于在web应用程序中实现搜索。它是一个事实上的行业搜索框架,仅仅因为它的先进功能,并且它是开源的。这些特性使企业能够在需要时编写自己的定制解决方案
过去,我和几个朋友用Java、Spring Boot和Elastic search编写了一个产品搜索服务软件。说到它的设计,我们会将大量的产品数据从传统的存储解决方案流和索引到Elastic搜索服务器,以使产品出现在搜索结果中
打算在搜索中显示的所有数据都从主存储复制到Elastic搜索存储中。此外,由于新数据被持久化在主存储中,它会实时异步地传递到Elastic服务器以进行索引
Log Processing(日志处理)
如果您的项目不是爱好项目,那么它很可能运行在集群中。当我们谈到运行大规模服务时,单片系统已经成为过去式。这么多微服务同时运行。一段时间内会产生大量的日志。而日志是回溯时间、跟踪错误和研究系统行为的唯一方法。
因此,为了全面地研究系统的行为,我们必须将所有的日志流传输到一个中心位置。在ELK (Elastic LogStash Kibana)堆栈等解决方案的帮助下,将日志输入到中央服务器上运行分析
Stream Processing Engines for Real-Time Events(实时事件的流处理引擎)
实时流媒体和数据处理是处理实时信息(如体育)的系统的核心组件。架构设置必须足够高效,能够吸收数据,分析数据,实时分析行为,并快速将更新信息推送给粉丝。毕竟,整个行业都依赖于此。
消息队列(如Kafka)、流计算框架(如Apache Storm、Apache Nifi、Apache Spark、Samza、Kinesis等)被用于实现在线应用中的实时大规模数据处理特性
这篇文章十分好Netflix’s real-time streaming platform
Data Pipelines
数据管道是数据处理基础设施的核心组件。它们促进了数据从一个点到另一个点的高效流动&还使开发人员能够对实时的数据流应用过滤器。
Features Of Data Pipelines(数据管道的特点)
- 确保数据流畅。
- 使业务能够在流式传输时应用过滤器和业务逻辑
- 避免数据流中的任何瓶颈和冗余。
- 促进数据的并行处理。
- 避免数据已损坏。
这些管道按照工程团队预定义的一组规则工作,数据可以在没有任何人工干预的情况下进行相应的路由。整个数据提取、转换、组合、验证、从多个数据流聚合到一个数据流等流程都是完全自动化的
传统上,我们使用ETL系统来管理所有的数据移动,但它们的一个主要限制是它们并不真正支持处理实时流数据。随着新时代由数据管道驱动的数据处理基础设施的发展,什么是可能的
ETL
Extract
是指从单个或多个数据源提取数据
Transform
意味着将提取的异构数据转换为基于业务设置的规则的标准化格式。
Load
指将转换后的数据移动到数据仓库或另一个数据存储位置,以进一步处理数据
ETL流与数据摄取流相同。它只是整个数据的移动是分批完成的,而不是通过数据管道实时流
同时,这并不意味着批处理方法已经过时。实时和批处理数据处理技术都是基于项目需求的.
当我们在接下来的课程中学习分布式数据处理的Lambda和Kappa架构时,您将对它有更深入的了解.
在上一课中,我介绍了一些流行的数据处理工具,如Apache Flink、Storm、Spark、Kafka等。所有这些工具都有一个共同之处,它们通过数据管道在分布式环境中促进集群中的数据处理.
Distributed Data Processing
分布式数据处理是指将大量数据分散到多个不同的节点上,在集群中运行,进行并行处理
所有节点执行并行分配的任务,通过一个节点协调器相互协作。Apache Zookeeper是业界非常流行的事实上的节点协调器。
由于节点是分布的,任务是并行执行的,这使得整个设置具有相当大的可伸缩性和高可用性。工作负载可以水平和垂直缩放。数据在集群中进行冗余和复制,以避免任何类型的数据丢失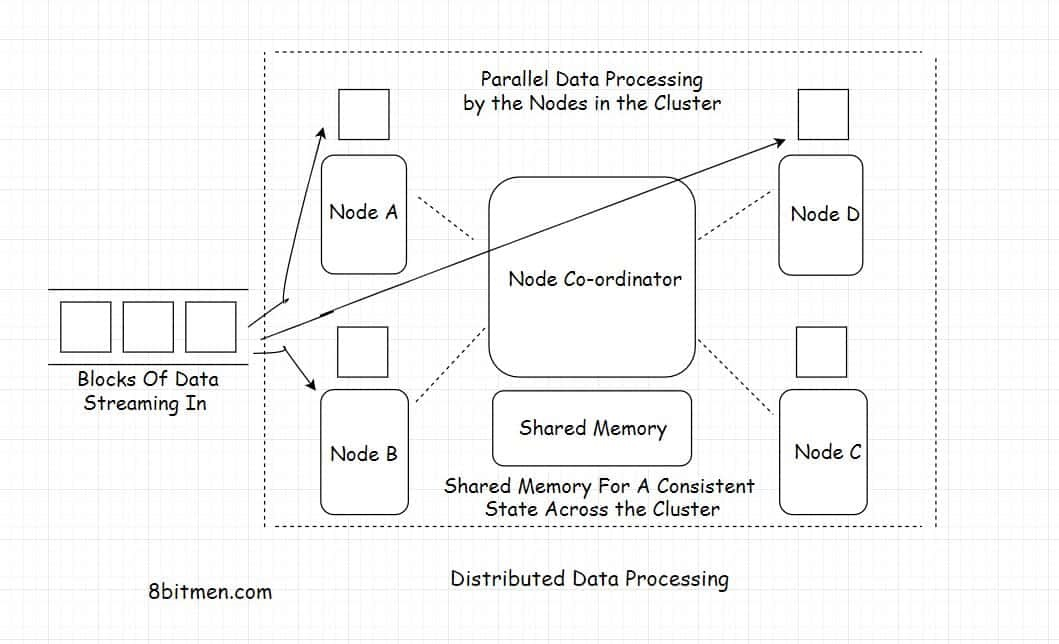
与在集中式数据处理系统上运行相比,在分布式环境中处理数据有助于以更少的时间完成任务
Distributed Data Processing Technologies(分布式数据处理技术)
MapReduce – Apache Hadoop
MapReduce是一个编程模型,用于管理集群中多台不同机器之间的分布式数据处理,将任务分布到多台机器上,并行运行工作,管理系统中不同部分的所有通信和数据传输
编程模型的Map部分涉及根据参数对数据进行排序,Reduce部分涉及汇总排序后的数据
MapReduce编程模型最流行的开源实现是Apache Hadoop。该框架被业内所有大腕用来管理系统中的大量数据。Twitter使用它进行分析。它被Facebook用来存储大数据。
Apache Spark
Apache Spark是一个开源的集群计算框架。它为批处理和实时流处理提供高性能。它可以与不同的数据源一起工作,并促进在集群中并行执行工作
Spark具有集群管理器和分布式数据存储功能。集群管理器可以方便集群中运行的不同节点之间的通信,而分布式存储可以方便大数据的存储。Spark与Cassandra、HDFS、MapReduce File System、Amazon S3等分布式数据存储进行无缝集成。
Apache Storm
Apache Storm是一个分布式流处理框架。在行业中,它主要用于处理大量的流数据。它有几个不同的用例,如实时分析、机器学习、分布式远程过程调用等
Apache Kafka
Apache Kafka是一个开源的分布式流处理和消息传递平台。它是用Java和Scala编写的,由LinkedIn开发
Kafka的存储层涉及分布式可伸缩的PUB /子消息队列。它有助于读取和写入数据流,如消息传递系统
Kafka在行业中被用来开发实时功能,如通知平台、管理大量数据流、监控网站活动和指标、消息传递、日志聚合。
Hadoop是批处理数据的首选,而Spark, Kafka & Storm是处理实时流数据的首选
#### Lambda Architecture(λ架构)
Lambda是一种分布式数据处理体系结构,它利用批处理和实时流数据处理方法来解决批处理方法产生的延迟问题。在将结果呈现给最终用户之前,它会连接这两种方法的结果
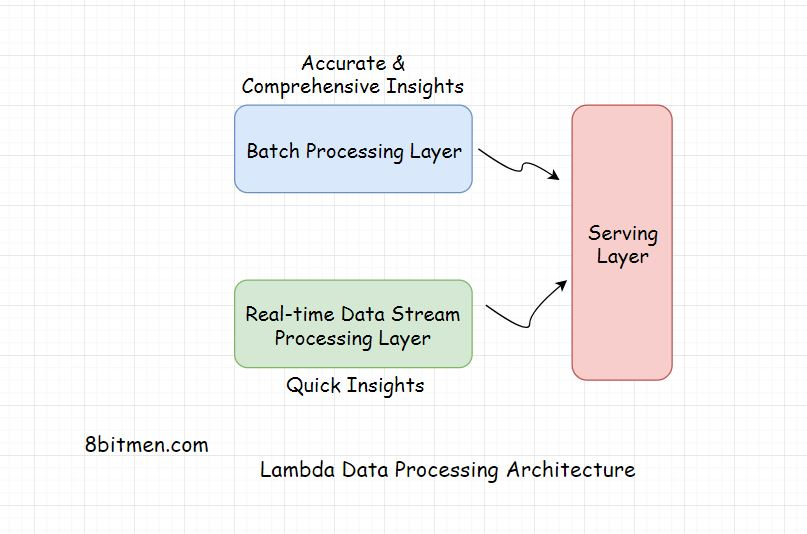
考虑到如今企业拥有的海量数据,批处理确实需要时间,但这种方法的准确性很高,结果也很全面
相反,实时流数据处理提供了快速的洞察力。在这种情况下,分析是在一小部分数据上运行的,因此与批处理方法相比,结果不是那么准确和全面
Lambda体系结构充分利用了这两种方法。
Layers Of the Lambda Architecture
- Batch Layer
- Speed Layer
- Serving layer
批处理层处理通过批处理数据获得的结果。
速度层从实时流数据处理中获取数据,
服务层结合从批处理和速度层获得的结果。
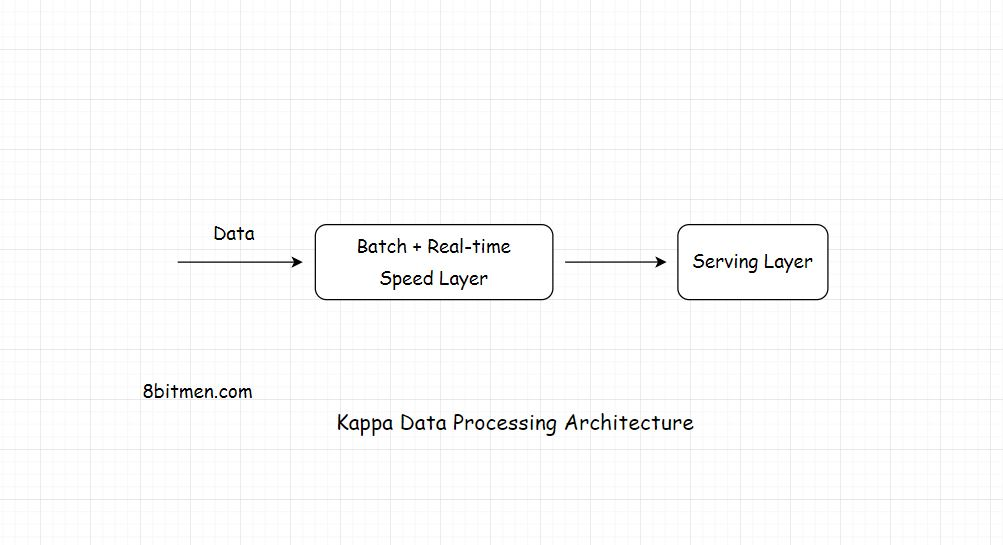
Kappa Architecture
在Kappa体系结构中,所有的数据都通过一个数据流管道流动,而Lambda体系结构具有不同的数据流层,它们汇聚成一个
该体系结构通过单个流管道将实时和批处理的数据流动,降低了不必管理处理数据的单独层的复杂性
Layers Of Kappa Architecture
Kappa只有两层。speed layer是流处理层,serving layer是最后一层
Kappa不是Lambda的替代品。这两个体系结构都有它们的用例
如果系统中的批处理和流分析结果相当相同,Kappa是首选。如果不是,则首选Lambda
尽管整个分布式数据处理方法看起来非常平滑和高效,但重要的是我们不要忘记,设置和管理分布式数据处理系统是一件重要的事情。完善这一制度需要多年的努力。此外,分布式系统不能保证数据的强一致性
Event Driven Architecture (事件驱动架构)
在编写现代Web 2.0应用程序时,你可能会遇到反应式编程(Reactive programming)、事件驱动架构(Event-driven architecture)、阻塞(Blocking)和非阻塞(Non-blocking)等概念。
你可能也注意到像NodeJS, Play, Tornado, Akka这样的技术。与传统技术相比,IO在现代应用开发中越来越受欢迎。
Blocking
在web应用程序中,阻塞意味着执行流程被阻塞,等待进程完成。直到流程完成,它才能继续。假设我们在一个函数中有一个10行代码块,每一行都会触发另一个执行特定任务的外部函数
当然,当执行流进入主函数时,它将从最上面的第一行开始执行代码。它将运行第一行代码并调用外部函数
此时,直到外部函数返回响应。流程被阻塞。流程不会进一步移动,它只是等待响应。除非我们通过注释和将任务移到一个单独的线程来添加异步行为。但在常规场景中,就像常规的基于crud的应用程序一样,这是不会发生的。
Non-Blocking
现在来谈谈非阻塞方法。在这种方法中,flow不会等待调用的第一个函数返回响应。它只是继续执行下一行代码。与阻塞方法相比,这种方法有点不太一致,因为函数可能不会返回任何东西或抛出错误,但仍然会执行下一个序列中的代码.
非阻塞方法简化了IO输入输出密集型操作。除了磁盘和其他基于硬件的操作,通信和网络操作也属于IO操作
Event-Driven Architecture
在应用程序中,通常有两种进程:CPU密集型进程和IO密集型进程。IO在web应用程序的上下文中意味着事件。大量IO操作意味着在一段时间内会发生大量事件。一个事件可以是任何事情,从一条tweet到一个按钮的点击,一个HTTP请求,一个接收到的消息,一个变量值的改变等等
我们知道Web 2.0实时应用程序有很多事件。例如,客户端和服务器之间有很多请求-响应,通常在在线游戏、消息应用程序等。发生得太频繁的事件被称为一连串事件。
非阻塞架构也被称为反应式架构或事件驱动架构。事件驱动架构在现代web应用程序开发中非常流行。
像NodeJS这样的技术,像Play、Akka这样的Java生态系统中的框架。io在本质上是非阻塞的,是为现代高io可伸缩的应用而构建的。
它们能够以最小的资源消耗处理大量并发连接。现代应用程序需要一个完全异步的模型来扩展。这些现代web框架在分布式环境中提供了更可靠的行为。它们被构建成在集群上运行,处理大规模并发场景,解决通常在集群环境中出现的问题。它们使我们在编写代码时不用担心处理多线程、线程锁、高IO导致的内存不足等问题
随着Web 2.0的出现,技术行业的人们觉得有必要改进这些技术,使其足够强大,以实现现代Web应用程序用例。Spring框架将Spring Reactor模块添加到核心Spring repo中。开发者写了NodeJS, Akka。io,玩等等。
因此,您可能已经意识到响应式事件驱动的应用程序很难用基于线程的框架实现。当处理线程、共享的可变状态时,锁使事情变得复杂得多。在事件驱动的系统中,一切都被视为流。抽象级别很好,开发人员不必担心管理底层内存
我相信你们已经很清楚这里应用的数据流用例,比如处理大量的交易事件、处理不断变化的股票市场价格、在线购物应用程序上的用户事件等。
NodeJS是一个单线程非阻塞框架,用来处理更多IO密集型任务。它有一个事件循环架构
与此同时,我想断言这样一个事实,即非阻塞技术的出现并不意味着传统技术已经过时。每个技术都有它的用例
NodeJS不适合CPU密集型任务。CPU密集型操作是指需要大量计算能力的操作,如图形渲染、运行ML算法、在企业系统中处理数据等。为了这些目的而选择NodeJS将是一个错误。
Web Hooks
假设您已经编写了一个API,它提供关于Baseball最新独家事件的信息。现在你的API被很多第三方服务使用,他们从API中获取信息,添加他们自己的风格并呈现给用户
但时不时地有这么多API请求,只是为了检查是否发生了特定的事件,这会让你的服务器崩溃。服务器几乎跟不上请求。消费者无法知道服务器上还没有可用的新信息,或者还没有发生事件。他们只是一直轮询API。这最终会在服务器上堆积不必要的负载,并可能导致服务器崩溃.
有什么办法可以减少服务器的负载吗,这就是web hooks
webhook更像是回调函数。“就像一旦有了新消息,就会打电话给你一样。”你继续你的工作.
webhook允许两个服务在没有中间件的情况下进行通信。它们拥有基于事件的机制。
使用 Web Hooks
要使用webhook,消费者需要用唯一的API Key向服务注册一个HTTP端点。这就像一个电话号码。事件发生时,打这个号码给我。我不会再给你打电话了
当新信息在后端可用时。服务器向消费者的所有注册端点发出一个HTTP事件,通知它们新的更新.
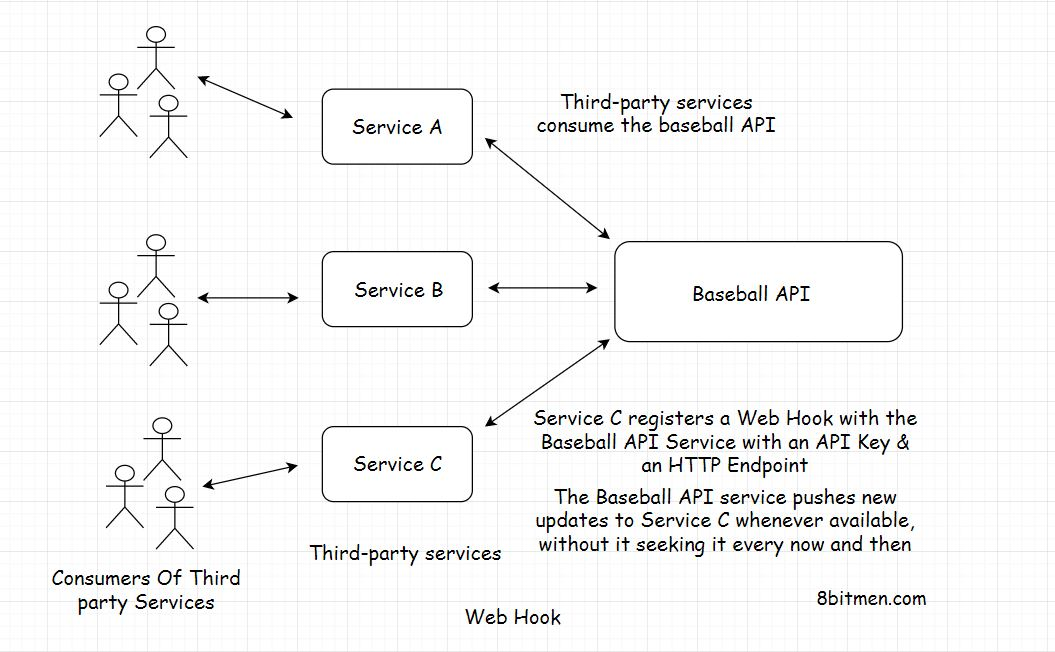
浏览器通知就是webhook的一个很好的例子。网站发布新内容时,会通知我们,而不是时不时地访问网站获取新信息
Shared Nothing Architecture(无共享架构)
在使用分布式系统时,您将经常听到“无共享架构”这个术语。当几个模块相互配合工作时。它们通常共享RAM,也称为共享内存。它们共享磁盘,也就是共享数据库。然后他们什么都不分享。模块或服务不共享任何内容的系统体系结构称为共享无内容体系结构
共享无任何体系结构意味着消除所有单点故障。每个模块都有自己的内存和磁盘。因此,即使系统中的几个模块发生故障,其他模块也不会受到影响。它还有助于提高可伸缩性和性能
### Hexagonal Architecture(六角结构)
该体系结构由三个组件组成
- Ports
- Adapters
- Domain
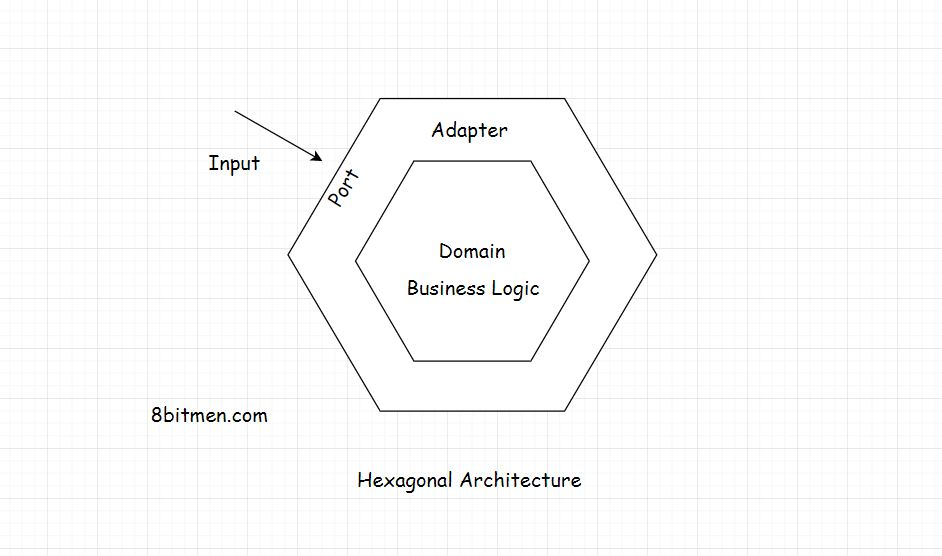
该体系结构的重点是使应用程序的不同组件:独立、松散耦合和易于测试
应用程序的设计应该是这样的:它可以由人工测试、自动化测试、模拟数据库、模拟中间件、有&没有UI、无需对代码做任何更改或调整
体系结构模式将域置于其核心,即业务逻辑。在外部,外层有端口和适配器。端口就像一个API,作为一个接口。应用程序的所有输入都通过界面
当使用jsp和存储过程时,我们仍然拥有分层的架构,UI层是独立的,持久化层是独立的,但业务逻辑与这些层是紧密耦合的。
相反,六边形模式有它的立场非常清楚,有一个内部组件持有业务逻辑&然后是外部层,端口和适配器,涉及数据库、消息队列、api和其他东西。
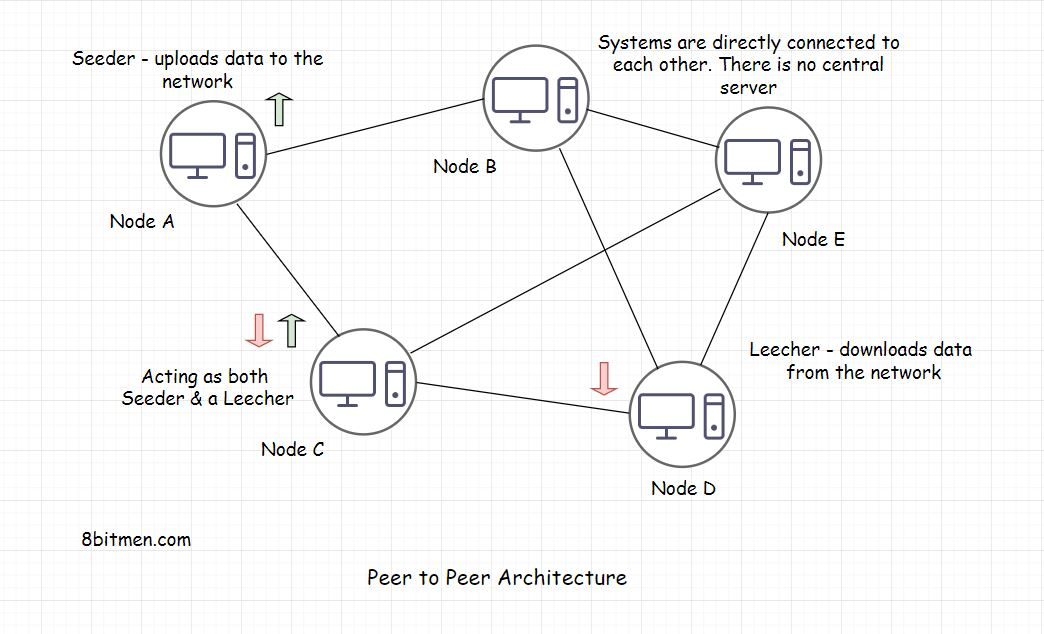
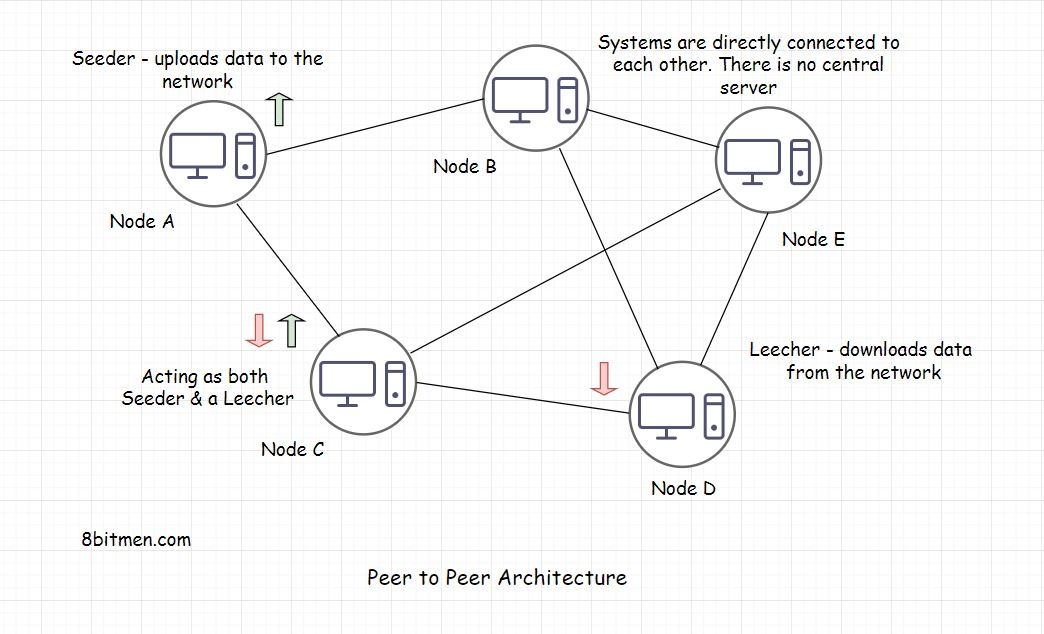
Peer to Peer Architecture(p2p架构)
P2P架构是区块链技术的基础。我们都在我们生命中的某些时候使用它来通过Torrent下载文件。所以,我猜你有点想到它是什么。您可能意识到种子,Leeching等的条款。
A Peer to Peer (P2P) Network
P2P网络是一种网络,其中也称为节点也可以在不需要中央服务器的情况下彼此通信。缺少中央服务器规定了单点故障的可能性。 网络中的所有计算机都具有平等的权利。节点同时充当播种器和leecher。所以,即使一些计算机/节点下降,网络和通信也仍然工作.
一个播种者是一个节点,它在自己的系统上托管数据,并提供带宽上传数据到网络,一个Leecher是一个节点,下载数据从网络。
A Central Server Mean
一个消息传递应用程序。当两个用户沟通,第一个用户发送一条消息从他的设备,服务器上的消息传递服务,将消息路由到目的地,也就是说,用户的设备接收消息.
服务器是中心服务器。这些系统也被称为集中式系统
缺点
首先,中央服务器可以访问您的所有消息。它可以阅读它,与同伴分享它,嘲笑它等等。因此,通信并不是真正安全的。尽管企业说整个信息管道都是加密的。但数据泄露还是会发生,政府可以获取我们的数据。数据被卖给第三方以牟取暴利。你认为这些通讯应用程序真的安全吗?处于食物链顶端的国家安全、企业官员是否应该使用这些中央服务器消息应用程序进行通信
其次,如果发生自然灾害,比如地震、僵尸攻击数据中心、大规模基础设施故障或组织破产等情况。我们被困住了,没有办法与世界各地的朋友交流。想想。
第三,假设你开始在社交媒体上创建内容,你有一个相当坚实的追随者,你每周花费100多个小时来发布有史以来最好的内容,并经过多年的努力才达到这个成功点。但突然有一天,公司突然对你说。嘿! !干得好,但是……由于某些我们不能谈论的原因,我们必须释放你的数据。我们只是不喜欢你的内容。Shift + Del,呼…你所有的数据都像精灵一样消失了。你接下来要做什么?如果你已经是一个内容创造者或活跃在社交媒体上,这种情况就会发生
P2P架构的工作模式
P2P对等体架构的设计围绕网络中的几个节点设计为同样充当客户端和服务器。
与TCP IP交换数据,就像在client-server模型中的HTTP协议上发生。P2P设计具有覆盖网络,用于通过TCP IP,使用户能够直接连接。它负责所有复杂性和沉重的举重。节点/对等体在此覆盖网络中索引和可发现。
在节点之间传输大文件的方法是将文件按非顺序分割成大小相等的块
一个系统托管75千兆字节的大文件。网络中的其他节点,需要文件,找到包含该文件的系统。然后,他们将文件下载在块中,同时重新托管下载的块,使其更可供其他用户使用。这种方法被称为分段的P2P文件传输
根据这些对等点在网络中相互连接的方式,将网络分为结构化、非结构化或混合模型
Unstructured Network
在一个非结构化的网络节点/对等体中继续随机连接。因此,没有结构,没有规则。只需连接和发展网络即可.
在这个体系结构设计中,没有节点的索引。为了搜索数据,我们必须扫描网络的每个节点。复杂度是O(n)其中n是网络中的节点数。这是非常耗费资源的
假设这个网络连接着十亿个系统。然后有一个文件只存储在网络中的一个系统中。在非结构化网络中,我们必须对网络中的每个系统进行搜索以找到文件
因此,如果在一个系统中搜索一个文件,比方说,需要1秒,而在整个网络中搜索则需要10亿秒。
非结构化网络的一些协议是Gossip, Kazaa和Gnutella。
Structured Network
与非结构化网络相比,对等网络的结构化P2P对等体保持了节点或拓扑的适当索引,这使得更容易搜索其中的特定数据。
这种网络实现了分布式哈希表来索引节点这个索引就像一本书的索引,我们在其中查找某一特定信息,而不是搜索它的每一页。
BitTorrent就是这类网络的一个例子
Hybrid Model(混合模式)
大多数区块链初创公司具有混合模型。一个混合模型意味着cherry-picking来自P2P,client-server等的混合模型,它是一个网络,包含p2p和client-server模型
正如我们所知,在p2p网络中,一个单独的实体并不拥有所有的控制权。因此,为了建立控制,我们需要建立自己的服务器。为此,我们需要一个client-server模型。
P2P网络提供了更多的可用性。要关闭区块链网络,你必须关闭全球范围内的所有节点。
P2P应用程序可以扩展到月球,而无需将负载放在单个实体或节点上。在理想的环境中,网络中的所有节点都平等地共享带宽和存储空间;当新用户使用该应用程序时,系统会自动扩展。
随着越来越多的人与你的数据进行交互,节点也会增加。数据存储和带宽成本为零,你不需要花钱购买第三方服务器来存储你的数据。没有第三方干预,数据是安全的。只和你想要分享的朋友分享。
在当今时代,对去中心化网络的狂热正在逐渐流行起来。我不能否认这是一个具有巨大潜力的颠覆性技术。区块链 加密货币就是一个例子。它已经席卷了金融领域.
例子:
- Tradepal
- 比特币、Peercoin等点对点数字加密货币。
- GitTorrent(一个分散的GitHub,使用BitTorrent和比特币)。
- Twister(一个分散的微博服务,使用WebTorrent作为媒体附件)。
- Diaspora(实现联邦架构的分散式社会网络)。
联邦体系结构是去中心化体系结构的扩展,用于去中心化的社交网络,这是我接下来要讨论的
Decentralized Social Networks(分散的社交网络)
简单地说,去中心化的社交网络拥有遍布全球的服务器,由像你我这样的个人托管。没有人对网络有自主的控制权,每个人都有平等的发言权
去中心化网络不需要面对任何可扩展性问题。去中心化网络的可扩展性与网络中加入和活跃用户的数量成正比
我们从自己的系统中托管数据,而不是将其发送到第三方服务器。没有人会偷听我们的谈话,也没有人有权随心所欲地修改你的数据
你可能听说过BYOD(Bring Your Own Device)这个词——自带设备。去中心化的社交网络要求你带上你自己的数据
在这些网络中,用户数据层是独立的&它们运行在专门为去中心化网络设计的标准化协议上。数据格式和协议在网络和应用程序中是一致的
所以,如果你想脱离某个特定的社交网络。你不会丢失你的数据;你的数据不会消失。你可以随身携带你的数据并将其输入到你接下来注册的应用程序中
网络上活跃着分散的社交网络,如Minds,** Mastodon**, Diaspora, Friendica,** Sola**等。
特点
Bring Your Own Data
正如我在前面提到的,您可以在无数的应用程序中随身携带数据。这是区块链经济的一个非常独特的特点,尤其是在电子游戏中。玩家购买的游戏内货币或内容(游戏邦注:如剑、力量等)可以在基于去中心化协议的其他游戏中使用。即使游戏工作室将游戏下线,购买的游戏内道具仍然具有价值。真正意义上来说,购买的东西会一直伴随你。
数据安全
不要再窃听私人组织对我们的数据。我们决定与谁分享我们的数据。数据对每个人都是加密的,包括网络的技术团队。不为个人利益出售我们的数据
对网络当事人进行经济补偿
像Diaspora, Sola, Friendica这样的网络已经推出了一些功能,可以在经济上补偿所有参与网络的各方。
用户会因为他们在网上分享的精彩内容而得到补偿。人们分享他们的计算能力来托管网络,并根据网络的经济政策以代币或股权或任何形式获得补偿。
参与网络审核的团队,编写新功能的开发者,通过在网络上发布内容相关的广告或平台上基于令牌的经济来获得补偿
Infrastructure Ease(简单化基础设施)
单个实体不必承担基础设施的全部成本,因为它是分散的。网络崩溃的可能性几乎为零。单独的开发人员可以构建很酷的东西,而不用担心服务器成本。数据就像区块链分类帐一样在节点间复制。所以,即使有几个节点故障,我们的数据也不会丢失
这些社交网络的协议和软件都是开源的,所以社区可以不断改进代码,不断构建令人惊叹的功能
ActivityPub就是一个例子,它是一个开放的去中心化的社交网络协议。它提供了一个API来修改和访问网络上的内容。同时,为了与联盟中的其他pods进行交流
金融科技行业的去中心化正在成为常态。
Federated Architecture(联邦架构)
联邦体系结构是分散体系结构的扩展。它支持像Mastodon, Minds, Diaspora等社交网络
语联邦在一般意义上是指一组相互交换信息的半自治实体。一个真实世界的例子是一个国家的不同的州,由州政府管理。他们是部分自治的,行使权力来保持事情顺利运行。然后,这些邦政府与中央政府共享信息,形成一个完全的自治政府
这只是一个例子。从技术角度来看,联邦模型正在不断的研究、发展和进化中。没有标准的规则。开发人员和架构师可以有自己的设计。毕竟,它是分散的。不受任何单一实体的控制
如何在去中心化的社交网络中实现联邦架构
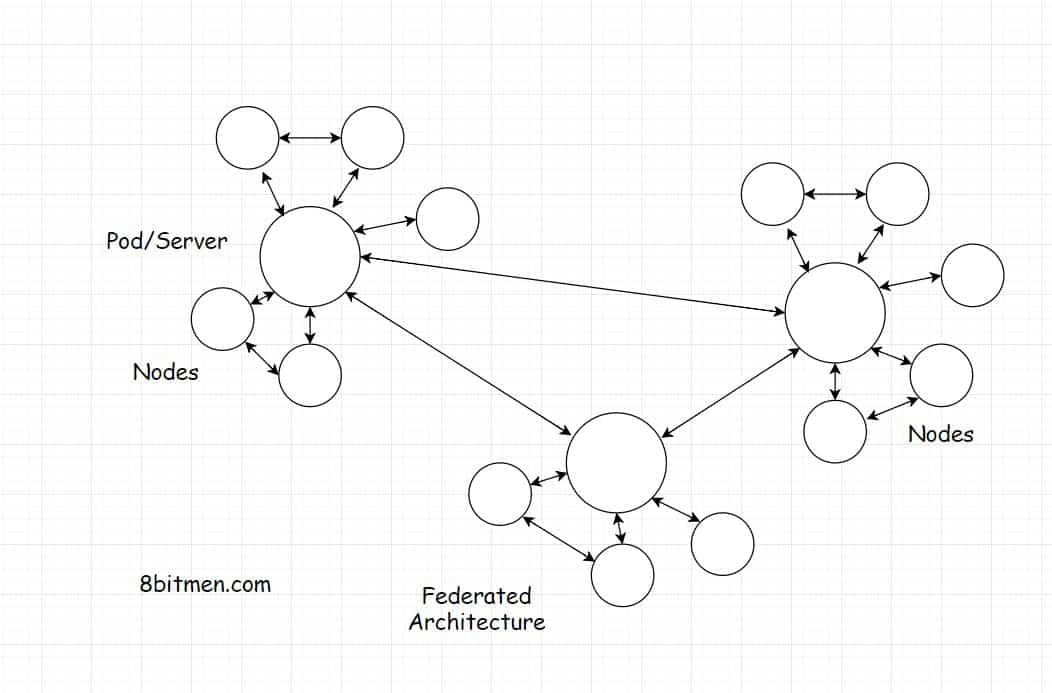
如下图所示。联邦网络有称为服务器或pods的实体。大量的节点订阅pods。网络中有几个互相链接的豆荚,它们互相分享信息。
这些pods可以由个人托管,因为这是在去中心化的网络中理想实现的。随着新的pods被托管和引入到网络中,网络不断增长
以防几个pods之间的联系暂时中断。网络还在运行。节点仍然可以通过它们订阅的节点彼此通信
pods的需求是什么
Pods可以帮助发现节点。在点对点网络中,没有办法发现其他节点&如果没有一个集中的节点注册表或其他东西,我们只能坐在黑暗中.
另一种方法是通过网络进行扫描,并尝试发现其他节点。那是一项非常费时且乏味的工作。为什么不直接用pod来代替呢
How to Pick the Right Server-Side Technology(如何选择合适的服务器端技术)
对于一个用例X,你应该总是选择一个技术y,这是没有经验法则的。一切都取决于我们的业务需求。每个用例都有其独特的需求。没有完美的技术,每件事都有它的优点和缺点。你可以随心所欲地创造。没有什么规则能阻止我们前进。好吧,说到这里。根据我的开发经验,我列出了一些应用程序开发领域的一般场景,或者可以说是常见的用例,以及适合这些场景的后端技术
Real-time Data Interaction(实时数据交互)
如果你正在构建一个应用程序,需要与后端服务器实时交互,如流数据来回。例如,即时消息应用、基于浏览器的大型多人游戏、实时协作文本编辑器或像Spotify、Netflix等音频视频流应用
您需要客户机和服务器之间的持久连接,还需要在后端采用非阻塞技术。我们已经详细讨论了这两个概念。
一些让我们能够编写这些应用程序的流行技术是NodeJS, Python有一个叫做Tornado的框架。如果你在Java生态系统中工作,你可以查看Spring Reactor, Play, akka .io。
一旦你开始研究这些技术,仔细研究开发者文档中给出的架构和概念。您将进一步了解事物是如何工作的,可以利用哪些其他技术和概念
Uber使用NodeJS编写他们的核心行程执行引擎。使用它,他们可以轻松地管理大量的并发连接。
Peer to Peer Web Application
如果你打算构建一个点对点的web应用程序,例如,P2P分布式搜索引擎或P2P直播电视广播服务,类似于LiveStation。
看看JavaScript, DAT, IPFS之类的协议。FreedomJS是一个构建P2P网络应用的框架,可以在现代浏览器中运行。 这是一个很好的阅读Netflix关于流媒体数据的点对点技术的研究 。
CRUD-based Regular Application(CRUD常规应用)
如果你有简单的用例,如基于crud的常规应用,如在线电影预订门户,税务申报应用等。CRUD(创建、读取、更新、删除)是当今企业构建的最常见的web应用形式。
无论是在线预订门户,应用程序收集用户数据或社交网站等,都在后端有一个MVC (Model View Controller)架构。尽管视图部分随着React、Angular、Vue等UI框架的兴起做了一些调整。
模型视图控制器模式保持不变。一些帮助我们实现这些用例的流行技术是Spring MVC,
Simple, Small Scale Applications(简单,小规模的应用)
如果您打算编写一个不涉及太多复杂的应用程序,如博客、简单的在线表单、与门户的IFrame中运行的社会媒体集成的简单应用程序。这包括基于网页浏览器的策略,航空公司,足球经理类游戏。你可以选择PHP。PHP最适合用于这类场景。我们也可以考虑其他的web框架,如Spring boot, Ruby on Rails,它们减少了冗余、配置和开发时间,并促进了快速开发。但与托管其他技术相比,PHP托管的成本要低得多
CPU & Memory Intensive Applications(CPU和内存密集型应用)
你是否需要在后台运行CPU密集型,内存密集型,繁重的计算任务,如大数据处理,并行处理,运行监控和分析大量的数据?
在运行CPU和内存密集型任务的系统中,性能是关键。处理大量数据有其成本。一个高延迟和内存消耗的系统可以摧毁一个科技公司的经济。
此外,常规的web框架和脚本语言并不意味着数字密集运算。
业界常用的技术是编写高性能、可扩展的分布式系统
c++中,它具有便于低级内存操作的特性。在编写分布式系统时,为开发人员提供对内存的更多控制。大多数加密货币都是使用这种语言编写的。
Rust是一种类似于c++的编程语言。它是为高性能和安全并发而构建的。它最近在开发者圈中获得了很大的人气
Java、Scala和Erlang也是不错的选择。大多数大型企业系统都是用Java编写的
Erlang是一种函数式编程语言,内置了对并发、容错和分发的支持。它促进了大规模可伸缩系统的开发。
Go是谷歌开发的一种编程语言,用于多核机器和处理大量数据
Julia是一种动态编程语言,用于高性能和运行计算和数值分析
Key Things To Remember When Picking the Tech Stack(选择技术堆栈时要记住的关键事情)
我从头开始写了无数个项目,花了无数个小时浏览网页,浏览技术和框架,以选择符合我需求的正确技术。
选择正确的技术堆栈是我们业务成功的关键。没有别的办法。我想我们都很清楚这个事实。一旦我们选择了技术和编码,就不应该回头看。我们当然负担不起。
Be Thorough with the Requirements(彻底满足需求)
我们应该非常清楚我们要建设什么。事情不应该是模糊的。如果我们不清楚需求,我们就无法选择正确的技术。一旦我们去打猎,我们应该清楚我们要找的是什么
例如,在寻找数据库时,我们应该清楚是要存储关系数据,还是面向文档、半结构化或完全没有结构。
我们是否在处理大量的数据,而这些数据预计将呈指数增长?或者,预计数据将以可控制的速度增长到一定限度?
单一的架构是否能很好地满足我们的需求,还是我们需要将应用程序分割成几个不同的模块?
将应用程序拆分为几个模块,在服务中使用异构技术,可以帮助我们在事情不顺利的情况下摆脱特定的技术。
See If What We Already Know Fits the Requirements(看看我们已经知道什么符合要求)
用我们已经掌握的技术构建新的应用程序会更容易。我们不需要经历随着新技术而来的陡峭的学习曲线.
而且,当我们使用我们所熟悉的技术时,事情会比较清晰。了解事实真相,熟悉错误、异常和修复它们的知识,有助于我们快速发布特性.
想象一下,一项你从未见过的新技术引发了一个异常,而且你也无法在网上找到解决方案。你是困。没有人帮助你,你听到的都是蟋蟀的叫声
Does the Tech We Have Picked Has An Active Community? How Is the Documentation & the Support(我们所选择的技术是否拥有一个活跃的社区)
我们选择的技术应该有一个活跃的社区。查看GitHub, StackOverflow等社区的参与情况。文档应该流畅,易于理解
社区越大越好。拥有一个活跃的社区意味着更新工具、库、框架等
看看是否有官方的技术支持?如果我们被困在路上,应该会有救援的。正确的
Is the Tech Being Used by Big Guns in Production(这一技术在生产中被使用了吗)
如果我们所选择的技术正在被行业中的大人物所使用,那么这就证明了它是经过实战考验的。它可以在生产中毫无顾虑地使用
我们可以肯定的是,我们将不会面临任何固有的可伸缩性、安全性或任何其他设计相关的技术问题。因为,代码库会不断地被新更新、漏洞和设计修复所修补
我们可以浏览这些公司的工程博客,了解他们是如何实现这项技术的
Check the License. Is It Open Source(检查许可证。它是开源的吗)
选择开源技术可以帮助我们编写自己的定制功能,以防原始解决方案没有这些功能。我们不需要依靠技术的创造者来创造新功能
此外,在资金方面,我们无需支付任何费用使用该产品。开源技术也有一个更大的社区,因为代码对所有人开放,任何人都可以派生它,开始编写新的功能或修复现有的已知bug。
Availability Of Skilled Resources on the Tech(技术资源的可用性)
一旦我们的业务开始增长。我们将需要一只手以快速的速度移动,并在规定的时间内推出新功能。在我们选择的技术领域,有足够的技术资源是很重要的.
例如,总是很容易找到一个MySQL管理员或Java开发人员,而不是寻找一个相对较新的技术熟练的资源.


Comments